Appearance
Java进阶教程 - 7 JDBC
JDBC(Java Database Connectivity)也就是通过 Java 来访问数据库。
JDBC 是 Java 提供的一套 访问数据库的标准 API,它的作用就是在 Java 程序和数据库之间搭建一座桥梁,让开发者通过统一的接口操作不同的数据库(如 MySQL、PostgreSQL、Oracle 等),而不必关心底层实现。
在这个章节你首先得有一点数据库方面的知识,不过不用紧张,也不用太多,你可以先学习一下 SQL/MySQL基础教程 ,了解一下数据库的基本操作。
首先准备一下数据库,我们这里就使用 MySQL 数据库了。
首先创建数据库和表:
sql
-- 创建数据库
CREATE DATABASE foooor_db CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
-- 创建一张用户表
CREATE TABLE tb_user (
id INT PRIMARY KEY AUTO_INCREMENT COMMENT '主键ID',
username VARCHAR(50) NOT NULL COMMENT '用户名',
balance INT UNSIGNED NOT NULL DEFAULT 0 COMMENT '余额',
create_time DATETIME NOT NULL COMMENT '创建时间'
);
-- 准备3条数据
INSERT INTO tb_user (username, balance, create_time) VALUES
('zhangsan', 150, '2025-09-15 10:30:00'),
('lisi', 200, '2025-09-20 14:15:00'),
('wangwu', 5, '2025-09-05 09:25:00');数据准备好了!下面就来演示一下使用 JDBC 实现数据的 CRUD。
CRUD 就是数据的增删改查:
C - Create(创建)
R - Read(读取)或 Retrieve(检索)
U - Update(更新)
D - Delete(删除)
7.1 使用JDBC查询数据库
下面从0开始来实现使用 Java 操作数据库。
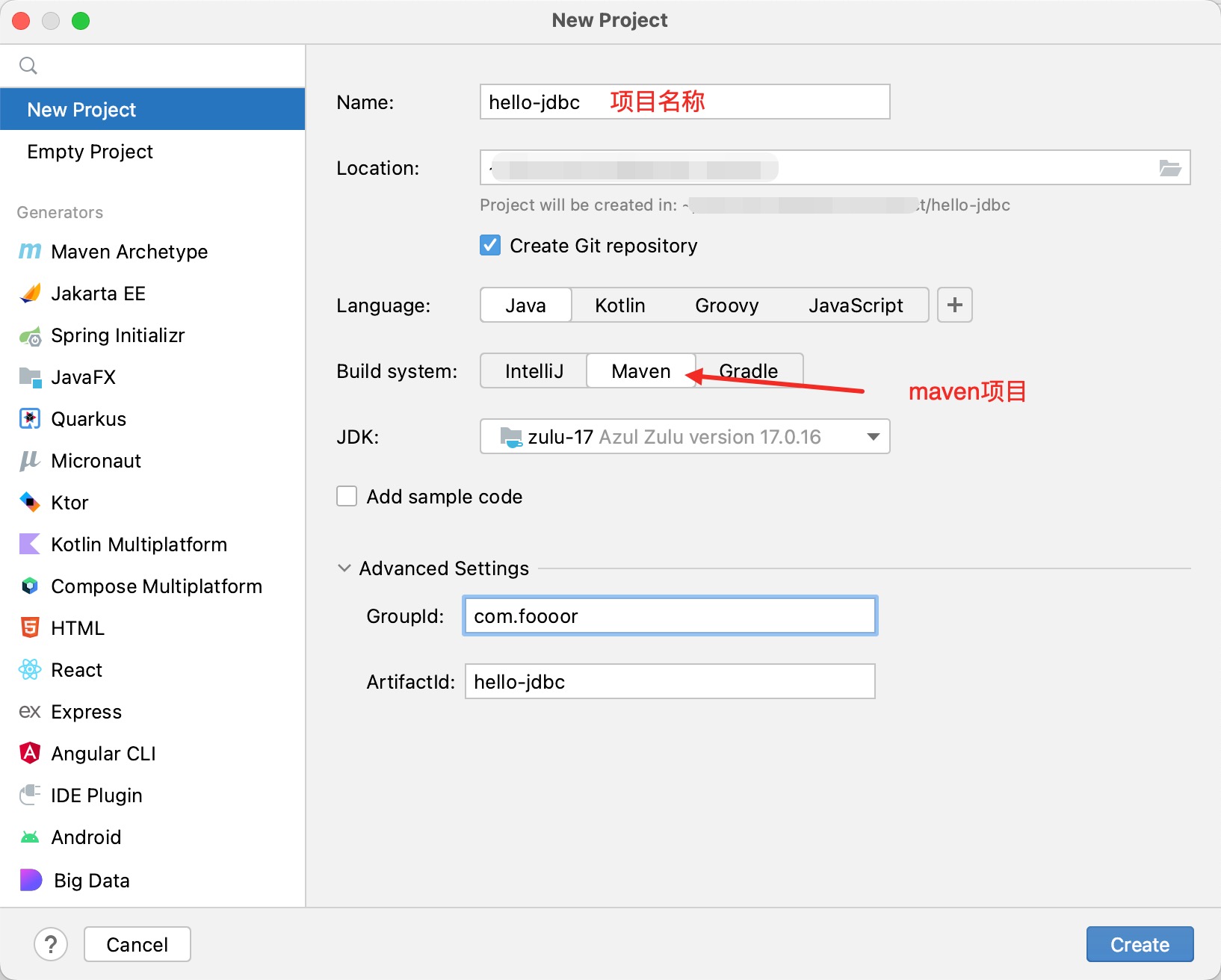
首先新建一个 Maven 项目,因为我们会使用到第三方的依赖,使用 Maven 管理比较方便。
1 创建项目
创建一个 Maven 项目:
2 引入MySQL依赖
在项目的 pom.xml 中添加 MySQL 的驱动 jar 包:
xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.foooor</groupId>
<artifactId>hello-jdbc</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<!-- 引入mysql驱动依赖,用于连接mysql数据库 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.33</version>
</dependency>
</dependencies>
</project>- 添加完成依赖,注意,要右键
pom.xml --> Maven --> Reload project一下,下载依赖。
Java 定义了统一的接口(JDBC),不同的数据库厂商会根据标准实现 JDBC 的接口,也就是驱动 jar 包,这样 Java 就能用统一方式访问不同数据库,而不关心具体的实现。
3 查询数据
下面就开始编写 Java 代码,实现数据的获取。
步骤主要分为以下几步:
- 加载驱动(JDBC 4.0+ 可以省略)
- 建立连接
- 执行 SQL
- 处理结果
- 关闭资源
首先创建一个 Java 类,我这里就叫 JdbcTest.java
java
package com.foooor.hellojdbc;
import java.sql.*;
import java.util.Date; // 注意,不是引入java.sql.Date
public class JdbcTest {
// 数据库连接信息
private static final String URL = "jdbc:mysql://localhost:3306/foooor_db?useSSL=false&serverTimezone=UTC";
private static final String USER = "root";
private static final String PASSWORD = "123456";
public static void main(String[] args) {
// 数据库连接对象
Connection conn = null;
// SQL 语句执行对象
PreparedStatement pstmt = null;
// 查询结果集对象
ResultSet rs = null;
try {
// 1. 注册 MySQL 驱动(可选,JDBC 4.0+ 可以省略,现在基本不用了)
Class.forName("com.mysql.cj.jdbc.Driver");
// 2. 获取数据库连接
conn = DriverManager.getConnection(URL, USER, PASSWORD);
String sql = "SELECT * FROM tb_user";
// 3. 创建 SQL 语句执行对象(PreparedStatement)
pstmt = conn.prepareStatement(sql);
// 4. 执行查询,返回结果集
rs = pstmt.executeQuery();
// 5. 遍历结果集
// rs.next() 会移动到下一行,如果有数据则返回 true
System.out.println("查询结果:");
while (rs.next()) {
int id = rs.getInt("id"); // 获取 id 列的值
String username = rs.getString("username"); // 获取 username 列的值
int balance = rs.getInt("balance"); // 获取 balance 列的值
// 获取 DATETIME 字段,返回 Timestamp
Timestamp timestamp = rs.getTimestamp("create_time"); // 获取create_time列的值
Date createTime = timestamp; // Timestamp是Date的子类,所以可以直接赋值
System.out.println(id + " | " + username + " | " + balance + " | " + createTime);
}
} catch (Exception e) {
// 捕获 SQL 异常并打印
e.printStackTrace();
} finally {
// 5. 关闭资源(顺序很重要!)
// 先关 ResultSet → 再关 PreparedStatement → 最后关 Connection
try {
if (rs != null) rs.close(); // 关闭结果集
} catch (SQLException e) {
e.printStackTrace();
}
try {
if (pstmt != null) pstmt.close(); // 关闭执行对象
} catch (SQLException e) {
e.printStackTrace();
}
try {
if (conn != null) conn.close(); // 关闭连接
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}- 按照步骤去实现,获取连接、执行SQL、处理结果、关闭连接,拿到结果 ResultSet 以后,需要逐条获取下一条数据,并依次获取其中的字段信息。
执行结果如下:
查询结果:
1 | zhangsan | 150 | 2025-09-15 18:30:00.0
2 | lisi | 200 | 2025-09-20 22:15:00.0
3 | wangwu | 5 | 2025-09-05 17:25:00.0上面是比较旧的 Java 语法,使用新的 JDK7 以后的 try-with-resources 语法,可以自动关闭资源。
像下面这样写就可以了:
java
package com.foooor.hellojdbc;
import java.sql.*;
import java.util.Date; // 注意,不是引入java.sql.Date
public class JdbcTest {
// 数据库连接信息
private static final String URL = "jdbc:mysql://localhost:3306/foooor_db?useSSL=false&serverTimezone=UTC";
private static final String USER = "root";
private static final String PASSWORD = "123456";
public static void main(String[] args) {
String sql = "SELECT * FROM tb_user";
// try-with-resources 写法
// 括号中的资源会在 try 代码块执行完毕后,自动调用 close() 方法,避免资源泄漏
try (
// 1. 获取数据库连接对象(Connection)
Connection conn = DriverManager.getConnection(URL, USER, PASSWORD);
// 2. 创建 SQL 语句执行对象(PreparedStatement)
PreparedStatement pstmt = conn.prepareStatement(sql);
// 3. 执行 SQL 查询
// executeQuery() 用于执行 SELECT 语句,返回一个结果集对象(ResultSet)
ResultSet rs = pstmt.executeQuery();
) {
// 4. 遍历结果集
// rs.next() 表示是否有下一行数据,第一次调用会指向第一行
while (rs.next()) {
// 通过列名或列索引获取数据
int id = rs.getInt("id"); // 获取 id 列的值(整型)
String username = rs.getString("username"); // 获取 username 列的值(字符串)
int balance = rs.getInt("balance"); // 获取 balance 列的值(字符串)
// 获取 DATETIME 字段,返回 Timestamp
Timestamp timestamp = rs.getTimestamp("create_time");
Date createTime = timestamp; // Timestamp是Date的子类,所以可以直接赋值
System.out.println(id + " | " + username + " | " + balance + " | " + createTime);
}
} catch (Exception e) {
// 捕获并打印 SQL 异常
e.printStackTrace();
}
// 注意:这里不需要写 finally 来关闭资源,因为 try-with-resources 会自动关闭
}
}7.2 SQL占位符
1 为什么需要占位符
在上面编写 SQL 的时候,是没有参数的,如果有参数的话,你可能会觉得这样写就好了:
java
String sql = "SELECT * FROM tb_user WHERE username = '" + username + "'";但是 SQL 拼接可能存在 SQL 注入的问题,例如当用户在前端输入 username 的值为 ' OR '1'='1 时,SQL就变为了:
sql
SELECT * FROM tb_user WHERE username = '' OR '1'='1''1'='1' 的条件是永远成立的,那么会查询出所有的数据,如果这是登录验证逻辑(只检查是否有结果),攻击者即可绕过认证,登录成功。
所以这里需要使用 SQL 占位符, ? 就是 SQL 的参数占位符。在 JDBC 里,当 SQL 中存在 ? 时,说明这是一个 预编译的 SQL,执行前需要通过 PreparedStatement 来填充参数。
2 占位符的使用
举个栗子,根据 id 来查询指定的用户:
java
package com.foooor.hellojdbc;
import java.sql.*;
import java.util.Date; // 注意,不是java.sql.Date
public class JdbcTest {
// 数据库连接信息
private static final String URL = "jdbc:mysql://localhost:3306/foooor_db?useSSL=false&serverTimezone=UTC";
private static final String USER = "root";
private static final String PASSWORD = "123456";
public static void main(String[] args) {
selectUserById(1);
}
/**
* 按 ID 查询单个用户
*/
public static void selectUserById(int id) {
String sql = "SELECT * FROM tb_user WHERE id = ?"; // SQL中使用占位符
try (
Connection conn = DriverManager.getConnection(URL, USER, PASSWORD);
PreparedStatement pstmt = conn.prepareStatement(sql)
) {
pstmt.setInt(1, id); // 设置第一个占位符(?)为 id
// 执行查询
ResultSet rs = pstmt.executeQuery();
// 遍历结果集(一般只有一条)
while (rs.next()) {
int uid = rs.getInt("id");
String username = rs.getString("username");
int balance = rs.getInt("balance");
Timestamp timestamp = rs.getTimestamp("create_time");
Date createTime = timestamp; // Timestamp是Date的子类,所以可以直接赋值
System.out.println(uid + " | " + username + " | " + balance + " | " + createTime);
}
} catch (SQLException e) {
e.printStackTrace();
}
}
}- 在上面的代码中, SQL 中的参数使用
?代替,然后使用PreparedStatement来设置对应位置的具体参数。这样可以避免 SQL 注入的风险。
7.3 增删改操作
上面演示的是查询操作,下面把增删改操作也演示一下:
java
package com.foooor.hellojdbc;
import java.sql.*;
import java.util.Date; // 注意,不是java.sql.Date
public class JdbcTest {
// 数据库连接信息
private static final String URL = "jdbc:mysql://localhost:3306/foooor_db?useSSL=false&serverTimezone=UTC";
private static final String USER = "root";
private static final String PASSWORD = "123456";
public static void main(String[] args) {
selectUserById(1);
insertUser("zhaoliu", 300, new Date());
updateUser(1, 200);
deleteUser(1);
selectAllUsers();
}
/**
* 查询所有用户
*/
public static void selectAllUsers() {
// 查询所有用户
String sql = "SELECT * FROM tb_user";
try (
Connection conn = DriverManager.getConnection(URL, USER, PASSWORD);
PreparedStatement pstmt = conn.prepareStatement(sql);
// 执行查询
ResultSet rs = pstmt.executeQuery()
) {
// 遍历所有结果
while (rs.next()) {
int uid = rs.getInt("id"); // 根据列名获取值
String username = rs.getString("username");
int balance = rs.getInt("balance");
Timestamp timestamp = rs.getTimestamp("create_time");
Date createTime = timestamp; // Timestamp是Date的子类,所以可以直接赋值
System.out.println(uid + " | " + username + " | " + balance + " | " + createTime);
}
} catch (SQLException e) {
e.printStackTrace();
}
}
/**
* 按 ID 查询单个用户
*/
public static void selectUserById(int id) {
String sql = "SELECT * FROM tb_user WHERE id = ?";
try (
Connection conn = DriverManager.getConnection(URL, USER, PASSWORD);
PreparedStatement pstmt = conn.prepareStatement(sql)
) {
pstmt.setInt(1, id); // 设置第一个占位符(?)为 id
// 执行查询
ResultSet rs = pstmt.executeQuery();
// 遍历结果集(一般只有一条)
while (rs.next()) {
int uid = rs.getInt("id"); // 根据列名获取值
String username = rs.getString("username");
int balance = rs.getInt("balance");
Timestamp timestamp = rs.getTimestamp("create_time");
Date createTime = timestamp; // Timestamp是Date的子类,所以可以直接赋值
System.out.println(uid + " | " + username + " | " + balance + " | " + createTime);
}
} catch (SQLException e) {
e.printStackTrace();
}
}
/**
* 新增用户
*/
public static void insertUser(String username, int balance, Date createTime) {
// 插入 SQL 语句
String sql = "INSERT INTO tb_user (username, balance, create_time) VALUES (?, ?, ?)";
try (
// 1. 获取数据库连接
Connection conn = DriverManager.getConnection(URL, USER, PASSWORD);
// 2. 预编译 SQL 语句
PreparedStatement pstmt = conn.prepareStatement(sql)
) {
// 3. 设置参数
pstmt.setString(1, username); // 这里是从1开始不是0
pstmt.setInt(2, balance);
pstmt.setTimestamp(3, new Timestamp(createTime.getTime()));
// 4. 执行 SQL
int rows = pstmt.executeUpdate();
System.out.println("插入成功,影响行数:" + rows);
} catch (SQLException e) {
e.printStackTrace();
}
}
/**
* 更新用户
*/
public static void updateUser(int id, int money) {
// 根据id更新
String sql = "UPDATE tb_user SET balance = balance + ? WHERE id = ?";
try (
Connection conn = DriverManager.getConnection(URL, USER, PASSWORD);
PreparedStatement pstmt = conn.prepareStatement(sql)
) {
// 设置参数
pstmt.setInt(1, money);
pstmt.setInt(2, id);
int rows = pstmt.executeUpdate();
System.out.println("更新成功,影响行数:" + rows);
} catch (SQLException e) {
e.printStackTrace();
}
}
/**
* 删除用户
* @param id 用户ID
*/
public static void deleteUser(int id) {
// 删除指定id的用户
String sql = "DELETE FROM tb_user WHERE id = ?";
try (
Connection conn = DriverManager.getConnection(URL, USER, PASSWORD);
PreparedStatement pstmt = conn.prepareStatement(sql)
) {
// 设置参数
pstmt.setInt(1, id);
int rows = pstmt.executeUpdate();
System.out.println("删除成功,影响行数:" + rows);
} catch (SQLException e) {
e.printStackTrace();
}
}
}- 其实操作都差不多,准备SQL、执行连接、要么执行查询,要么执行更新(增、删、改)、获取结果、关闭资源(或自动关闭)。
7.4 事务
事务是一组数据库操作的集合,这些操作要么 全部成功,要么 全部失败。
例如张三给李四转账100,要张三的账户减去100,李四的账户加上100,这是一组操作,必须全部成功,不能张三账户减去100成功,李四账户加上100失败,这会导致数据错误。
在 JDBC 中,默认情况下每条 SQL 都是一个单独的事务(即自动提交模式,autoCommit=true)。你执行一条更新的 SQL ,它会立即提交到数据库。
所以我们在进行增、删、改操作(查询不需要)的时候,如果涉及到多条 SQL,就需要关闭自动提交,手动开启事务,并手动提交事务。
所以操作需要分为以下步骤:
- 关闭事务自动提交;
- 手动开启事务;
- 执行多条SQL;
- 手动提交事务;
- 执行出错,回滚事务。
下面使用一个例子演示一下:
我们这里将张三的账户 -100,将李四的账户 +100,如果中间出错,就回滚所有操作。
java
package com.foooor.hellojdbc;
import java.sql.*;
import java.util.Date; // 注意,不是java.sql.Date
public class JdbcTest {
// 数据库连接信息
private static final String URL = "jdbc:mysql://localhost:3306/foooor_db?useSSL=false&serverTimezone=UTC";
private static final String USER = "root";
private static final String PASSWORD = "123456";
public static void main(String[] args) {
testTransaction();
}
public static void testTransaction() {
Connection conn = null;
PreparedStatement updateStmt1 = null;
PreparedStatement updateStmt2 = null;
try {
// 1. 获取连接
conn = DriverManager.getConnection(URL, USER, PASSWORD);
// 2. 关闭自动提交,开启事务
conn.setAutoCommit(false);
// 3. 更新zhangsan的账户,减去100
String updateSql1 = "UPDATE tb_user SET balance = balance - ? WHERE username = ?";
updateStmt1 = conn.prepareStatement(updateSql1);
updateStmt1.setInt(1, 100);
updateStmt1.setString(2, "zhaoliu");
int rows1 = updateStmt1.executeUpdate();
if (rows1 == 0) {
// 如果没有更新到数据,则抛出异常,会被catch捕获,然后回滚事务
throw new SQLException("更新张三账户失败!");
}
// 4. 更新lisi的账户,加上100
String updateSql2 = "UPDATE tb_user SET balance = balance + ? WHERE username = ?";
updateStmt2 = conn.prepareStatement(updateSql2);
updateStmt2.setInt(1, 100);
updateStmt2.setString(2, "lisi");
int rows2 = updateStmt2.executeUpdate();
if (rows2 == 0) {
// 如果没有更新到数据,则抛出异常,会被catch捕获,然后回滚事务
throw new SQLException("更新李四账户失败!");
}
// 5. 提交事务
conn.commit();
System.out.println("事务提交成功!");
} catch (Exception e) {
e.printStackTrace();
try {
if (conn != null) {
// 6. 出错时回滚
conn.rollback();
System.out.println("事务已回滚!");
}
} catch (SQLException ex) {
ex.printStackTrace();
}
} finally {
try {
if (conn != null) {
// 7. 恢复自动提交
conn.setAutoCommit(true);
}
} catch (Exception e) {}
try { if (updateStmt1 != null) updateStmt1.close(); } catch (Exception e) {}
try { if (updateStmt2 != null) updateStmt2.close(); } catch (Exception e) {}
try { if (conn != null) conn.close(); } catch (Exception e) {}
}
}
}- 如果上面有一个步骤出错,就会抛出异常,捕获异常以后,就会回滚事务;
- 需要注意的点:首先关闭自动提交,执行完成后需要恢复自动提交,同时出现异常的时候,要回滚事务。
7.5 封装工具类
上面在进行增、删、改、查的时候,因为每一次都要进行连接、关闭等操作,每一次操作都要进行很多重复的操作,所以我们可以将一些重复的操作封装成一个工具类。
例如我封装成一个 JdbcHelper.java,代码如下:
java
package com.foooor.hellojdbc;
import java.sql.*;
import java.util.*;
public class JdbcHelper {
private static final String URL = "jdbc:mysql://localhost:3306/foooor_db?useSSL=false&serverTimezone=UTC";
private static final String USER = "root";
private static final String PASSWORD = "123456";
static {
try {
// 注册驱动(JDBC 4.0+ 可省略)
Class.forName("com.mysql.cj.jdbc.Driver");
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
/**
* 通用查询方法
* @param sql SQL语句,支持 ? 占位符
* @param params 参数列表
* @return 每行数据为一个 Map
*/
public static List<Map<String,Object>> query(String sql, List<Object> params) {
List<Map<String,Object>> list = new ArrayList<>(); // 结果放在List中,每一行数据是一个Map
Connection conn = null;
PreparedStatement pstmt = null;
ResultSet rs = null;
try {
conn = DriverManager.getConnection(URL, USER, PASSWORD);
pstmt = conn.prepareStatement(sql);
// 遍历参数,设置占位符的值
if (params != null) {
for (int i = 0; i < params.size(); i++) {
pstmt.setObject(i + 1, params.get(i));
}
}
rs = pstmt.executeQuery();
ResultSetMetaData meta = rs.getMetaData();
int columnCount = meta.getColumnCount(); // 获取查询到的结果集的列数
while (rs.next()) {
Map<String,Object> row = new HashMap<>(); // 每一行数据封装为一个map
for (int i = 1; i <= columnCount; i++) {
row.put(meta.getColumnLabel(i), rs.getObject(i)); // 列名作为键,对应的值作为值
}
list.add(row);
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
close(rs, pstmt, conn); // 关闭结果集、语句和连接
}
return list;
}
/**
* 通用更新方法(INSERT / UPDATE / DELETE)
* 自动事务管理:成功提交,失败回滚
*/
public static int update(String sql, List<Object> params) {
Connection conn = null;
PreparedStatement pstmt = null;
int affectedRows = 0;
try {
conn = DriverManager.getConnection(URL, USER, PASSWORD);
// 首先记录一开始的提交状态,后面要恢复,因为一开始的提交模式有可能是自动提交有可能是手动提交,最后恢复为一开始的状态
boolean originalAutoCommit = conn.getAutoCommit();
try {
conn.setAutoCommit(false); // 关闭自动提交,开启事务
pstmt = conn.prepareStatement(sql);
// 设置占位符的值
if (params != null) {
for (int i = 0; i < params.size(); i++) {
pstmt.setObject(i + 1, params.get(i));
}
}
affectedRows = pstmt.executeUpdate(); // 获取到影响到的行
conn.commit(); // 提交事务
} catch (SQLException e) {
e.printStackTrace();
if (conn != null) conn.rollback(); // 失败则回滚事务
} finally {
if (conn != null) {
try {
conn.setAutoCommit(originalAutoCommit); // 恢复一开始的提交状态
} catch (SQLException e) {
e.printStackTrace();
}
}
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
close(null, pstmt, conn); // 关闭语句和连接
}
return affectedRows;
}
/**
* 关闭资源
*/
private static void close(ResultSet rs, Statement stmt, Connection conn) {
if (rs != null) { try { rs.close(); } catch (SQLException e) { e.printStackTrace(); } }
if (stmt != null) { try { stmt.close(); } catch (SQLException e) { e.printStackTrace(); } }
if (conn != null) { try { conn.close(); } catch (SQLException e) { e.printStackTrace(); } }
}
}- 在上面的代码中,主要封装了两个方法,一个是查询,一个是更新;
- 我们将SQL的参数作为方法的参数,通过列表传入,然后设置给
PreparedStatement。 - 查询的结果数据,每一条数据作为一个 Map ,其中每一列的数据是 Map 中一条记录。
- 你也可以自己封装自己的 JDBC 工具类,或者网上找别人写的。
那么有了上面的工具类,我们查询的时候,可以这么调用了:
java
// 查询
List<Object> params = new ArrayList<Object>();
params.add(2);
// 执行查询
List<Map<String,Object>> users = JdbcHelper.query(
"SELECT * FROM tb_user WHERE id = ?",
params
);
// 得到查询结果
for (Map<String,Object> row : users) {
System.out.println(row);
}同样,更新、删除、修改也可以调用更新的方法:
java
List<Object> params = new ArrayList<Object>();
params.add("new_name");
params.add(1);
int rows = JdbcHelper.update(
"UPDATE tb_user SET username = ? WHERE id = ?",
params
);
System.out.println("影响行数:" + rows);这样操作就方便和清晰很多了。
当然上面工具类的局限性很大,这里只是做一个演示,你可以根据你的需要进行封装。
7.6 数据库连接池
数据库连接(Connection)是一个非常 重量级资源,建立和释放的代价很大,需要经历很多的步骤,例如:
- TCP 连接 → 握手
- 用户认证
- 分配数据库资源
如果每次 SQL 都去 DriverManager.getConnection(),执行完再 close(),就会频繁创建销毁,性能非常差。
而且可以避免无限制创建数据库连接,防止数据库压力过大。
为了提高资源的利用率,我们可以使用数据库了连接池,主要的原理如下:
- 预先创建一批连接(多个),放在一个池子里。
- 应用程序要用连接时,从池子里取;用完后不会
close(),不会销毁连接,而是归还池子。 - 下次谁再使用的时候,再从池子中获取一个链接。
- 这样大大减少了连接的创建/销毁次数,提高性能。
因为同时会有多个线程或用户操作数据库,所以在初始化的时候可以创建多个连接放到连接池中,后面连接不够了,可以再创建新的连接,同时可以设置最大连接数,如果超过最大连接数了,就不会创建新的连接了。同时后面获取连接要看连接池中有没有空闲的连接,如果没有就要等别人释放连接,将连接重新归还到连接池,才能获取到连接。
一般常见连接池有:
- Druid(阿里开源,功能全面,监控强大)
- HikariCP(Spring Boot 默认,性能极高)
- C3P0、DBCP(老牌,但现在较少用)
下面我们就简单介绍一下 Druid 的使用。
1 引入依赖
在项目的 pom.xml 中引入 Druid 的依赖:
xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.foooor</groupId>
<artifactId>hello-jdbc</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<!-- 引入mysql驱动依赖,用于连接mysql数据库 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.33</version>
</dependency>
<!-- 引入druid依赖,提供数据库连接池 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.2.27</version>
</dependency>
</dependencies>
</project>2 使用连接池
这里直接在前面编写的工具类 JdbcHelper.java 的基础上进行修改。
操作也很简单,我们只需要修改获取数据库连接的地方就可以了,通过 DruidDataSource 去获取连接,这样数据库连接都交由 DruidDataSource 管理。
java
package com.foooor.hellojdbc;
import com.alibaba.druid.pool.DruidDataSource;
import java.sql.*;
import java.util.*;
public class JdbcHelper {
private static final DruidDataSource dataSource = new DruidDataSource();
static {
// 基础配置
dataSource.setUrl("jdbc:mysql://localhost:3306/foooor_db?useSSL=false&serverTimezone=UTC");
dataSource.setUsername("root");
dataSource.setPassword("123456");
dataSource.setDriverClassName("com.mysql.cj.jdbc.Driver");
// 连接池配置(可调节)
dataSource.setInitialSize(5); // 初始化连接数
dataSource.setMaxActive(20); // 最大活跃连接数
dataSource.setMinIdle(5); // 最小空闲连接数
dataSource.setMaxWait(60000); // 最大等待时间(毫秒)
}
/**
* 通用查询方法
* @param sql SQL语句,支持 ? 占位符
* @param params 参数列表
* @return 每行数据为一个 Map
*/
public static List<Map<String,Object>> query(String sql, List<Object> params) {
List<Map<String,Object>> list = new ArrayList<>();
Connection conn = null;
PreparedStatement pstmt = null;
ResultSet rs = null;
try {
conn = dataSource.getConnection(); // 从连接池获取连接
pstmt = conn.prepareStatement(sql);
if (params != null) {
for (int i = 0; i < params.size(); i++) {
pstmt.setObject(i + 1, params.get(i));
}
}
rs = pstmt.executeQuery();
ResultSetMetaData meta = rs.getMetaData();
int columnCount = meta.getColumnCount();
while (rs.next()) {
Map<String,Object> row = new HashMap<>();
for (int i = 1; i <= columnCount; i++) {
row.put(meta.getColumnLabel(i), rs.getObject(i));
}
list.add(row);
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
close(rs, pstmt, conn);
}
return list;
}
/**
* 通用更新方法(INSERT / UPDATE / DELETE)
* 自动事务管理:成功提交,失败回滚
*/
public static int update(String sql, List<Object> params) {
Connection conn = null;
PreparedStatement pstmt = null;
int affectedRows = 0;
try {
conn = dataSource.getConnection();
boolean originalAutoCommit = conn.getAutoCommit();
try {
conn.setAutoCommit(false);
pstmt = conn.prepareStatement(sql);
if (params != null) {
for (int i = 0; i < params.size(); i++) {
pstmt.setObject(i + 1, params.get(i));
}
}
affectedRows = pstmt.executeUpdate();
conn.commit();
} catch (SQLException e) {
e.printStackTrace();
if (conn != null) conn.rollback();
} finally {
if (conn != null) {
try {
conn.setAutoCommit(originalAutoCommit); // 恢复原始事务模式
} catch (SQLException e) {
e.printStackTrace();
}
}
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
close(null, pstmt, conn);
}
return affectedRows;
}
/**
* 关闭资源(归还连接到连接池)
*/
private static void close(ResultSet rs, Statement stmt, Connection conn) {
if (rs != null) { try { rs.close(); } catch (SQLException e) { e.printStackTrace(); } }
if (stmt != null) { try { stmt.close(); } catch (SQLException e) { e.printStackTrace(); } }
// 注意:conn.close() 底层不会关闭连接,而是归还连接到连接池
if (conn != null) { try { conn.close(); } catch (SQLException e) { e.printStackTrace(); } }
}
}- 使用是很简单的,就是一开始创建了一个
DruidDataSource数据源,后面获取数据库连接的时候,通过这个数据源获取就可以了。 - 其他的代码和之前是一样的,不用动。
- 在最后关闭连接的时候,底层不是真的关闭了连接,而是将连接归还给连接池。
通过连接池,可以提高数据库的访问效率,减少开销,还可以帮我们管理连接,控制并发,避免数据库压力过大。
上面操作 JDBC 操作数据库,是比较基础和原始的方式,每次查询都要手动写 SQL、创建 Connection、PreparedStatement、ResultSet,用完还要自己关闭资源。查询结果要手动解析,把每一行封装成对象或 Map,操作都比较麻烦。
在现在的项目中,我们一般会使用一些第三方的框架来操作数据库,例如 Spring JdbcTemplate、MyBatis、Hibernate等(现在用的少了),框架会帮我们完成数据的封装,简化我们的操作,但是底层还是通过 JDBC来实现的。
内容未完......