# Python教程 - 7 面向对象
面向对象,首先涉及到的两个概念就是:类 和 对象。
什么是类?
类就是对现实事物的抽象设计。
例如设计学生的类,可能包括属性:学号,姓名、年龄、性别等。
设计狗的类,可能包括属性:名字、年龄、品种。
类表示的是对一个事物的抽象,不是具体的某个事物。
什么是对象?
对象就是一个具体的实例,这个实例是从类派生出来的。
我们将类的属性赋值,就产生了一个个实例,也就是对象。
例如通过学生的类,我们赋值:学号=001,姓名=张三,年龄=16,性别=男,班级=三年二班,产生了就是一个名字叫张三的具体的学生,这样我们通过给类可以派生出一个个不同属性值的对象,李四、王五、赵六...。
# 7.1 类和对象
# 1 类的定义
类中可以定义属性和行为,属性也叫类的成员变量,表示这个类有哪些数据信息,行为也叫成员方法,表示这个类能干什么。
例如,对于学生类而言,学号、姓名、年级就是属性,学习这个行为,可以定义为方法。
那么我们可以定义以下学生类:
# 定义类使用class关键字,后面跟类名
class Student:
def __init__(self):
self.sid = None # 定义学号
self.name = None # 定义姓名
self.age = None # 定义年龄
def study(self):
print(f"我是{self.name}, 我在学习")
2
3
4
5
6
7
8
9
在上面的类中,在 __init__ 方法中,通过 self 关键字定义了三个成员变量(sid、name、age), __init__ 方法是类的构造方法,会在使用类创建对象的时候自动调用。
定义了一个成员方法 study,定义实例方法和之前定义函数很相似,不同的是,实例方法的第一个参数是 self,后面才是我们自定义的参数。这个 self 现在暂时不用理会,固定的写法。
在成员方法中访问属性,需要使用 self.属性 。
# 2 类的使用
上面我们定义好类了,现在可以使用类来创建对象了。
"""定义类"""
class Student:
def __init__(self):
self.sid = None # 定义学号
self.name = None # 定义姓名
self.age = None # 定义年龄
def study(self):
print(f"我是{self.name}, 我在学习")
"""使用类来创建对象"""
stu = Student()
stu.sid = "001" # 为属性赋值
stu.name = "逗比笔记"
stu.age = 18
stu.study() # 调用成员方法
stu.age = 19 # 修改实例变量
print(stu.age) # 访问属性
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
通过 类名() 可以创建一个对象,得到对象后,我们可以通过 对象.属性 来给变量赋值、访问变量、修改变量的值。
使用 对象.方法() 可以调用实例方法,调用的时候忽略成员方法的第一个 self 参数。
执行结果:
我是逗比笔记, 我在学习 19
面向对象编程就是先设计类,然后通过类创建对象,由对象做具体的工作。
面向过程编程关心的是实现功能的步骤,而面向对象编程更关心由谁来实现功能。
# 3 self的作用
上面方法第一个参数的 self 表示什么?
self 表示调用当前方法的对象本身。
举个栗子:
下面的代码,我们定义了学生类,创建了两个学生的对象。
"""定义类"""
class Student:
def __init__(self):
self.sid = None # 定义学号
self.name = None # 定义姓名
self.age = None # 定义年龄
def study(self):
print(f"我是{self.name}, 我在学习")
"""使用类来创建对象"""
stu1 = Student() # 创建第一个对象
stu1.sid = "001" # 为第一个对象赋值
stu1.name = "张三"
stu1.age = 18
stu2 = Student() # 创建第二个对象
stu2.sid = "002" # 为第二个对象赋值
stu2.name = "李四"
stu2.age = 19
stu1.study()
stu2.study()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
执行结果:
我是张三, 我在学习 我是李四, 我在学习
self 表示的当前调用成员方法的对象本身。
当我们使用 stu1 调用 study() 方法的时候,self 就是指 张三 这个对象,那么 self.name 的值就是 张三 ;当我们使用 stu2 调用study() 方法的时候,self 就是指 李四 这个对象,那么 self.name的值就是 李四。
# 4 构造方法初始化
上面我们在创建对象后,分别使用 self.属性 来给对象的属性来进行赋值。我们也可以在创建对象的时候,直接传递属性值给 __init__ 方法进行初始化, __init__ 方法是类的构造方法。
举个例子:
"""定义类"""
class Student:
def __init__(self, sid, name, age):
self.sid = sid # self.sid表示属性,sid表示构造方法参数
self.name = name
self.age = age
def study(self):
print(f"我是{self.name}, 我在学习")
"""使用类来创建对象"""
stu1 = Student("001", "张三", 18)
stu2 = Student("002", "李四", 19)
stu1.study()
stu2.study()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
上面使用 __init__ 方法定义了多个参数,将参数赋值给成员变量,这样就可以在创建对象的时候,可以通过 类名(参数) 在括号中传递参数,代码要简洁很多。
# 5 定义一个空类
我们有时候定义一个类,但是类的细节还没有想好,只是想定义一个空类,那么就需要pass关键字:
class Student:
pass # 使用pass关键字来定义空类
2
我们在编写代码的时候,可能先构建功能实现的步骤,然后再完善具体的方法,所以我们可能需要定义空的方法,后面再来完善方法的细节。
使用pass关键字定义空方法:
def study():
pass # 使用pass关键字来定义空方法
2
# 6 类变量
上面我们定义的属性和方法,是实例变量和实例方法,也叫成员变量和成员方法。
实例变量对于每个实例而言,是独立的数据,每个对象之间相互不会影响。创建一个对象,就会开辟独立的内存空间保存对象的实例变量数据。但是无论创建多少对象,实例方法只有一份,所有对象共享,通过传入的第一个参数self,来确定是哪个对象调用了实例方法。
在类中还可以定义各个对象共享的数据,也就是类变量。
打个比方,我们定义了一个Student类,然后通过Student类来创建对象,我们想知道一共创建了多少个Student对象,应该如何操作呢?
我们可以通过定义类变量来实现:
class Student:
stu_count = 0;
def __init__(self, sid, name, age):
self.sid = sid # 学号
self.name = name # 姓名
self.age = age # 年龄
Student.stu_count += 1
def study(self):
print(f"我是{self.name}, 我在学习")
"""使用类来创建对象"""
stu1 = Student("001", "张三", 18)
stu2 = Student("002", "李四", 19)
stu2 = Student("003", "王五", 17)
print(Student.stu_count)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
在上面的代码中,我们定义了一个类,然后在类中定义了一个 stu_count 变量,该变量不在方法中定义,也就是累变量。
类变量通过 类名.变量 来赋值和访问。
执行结果:
3
# 7 类方法
除了类变量,还有类方法,类方法的作用就是用来操作类变量。
类方法需要在方法上添加 @classmethod 注解,类方法至少有一个形参,该形参用于绑定类,一般命名为 cls 。
class Student:
stu_count = 0;
def __init__(self, sid, name, age):
self.sid = sid # 学号
self.name = name # 姓名
self.age = age # 年龄
Student.stu_count += 1
@classmethod
def get_stu_count(cls):
print(f"一共创建了{Student.stu_count}个学生")
stu1 = Student("001", "张三", 18)
stu2 = Student("002", "李四", 19)
stu2 = Student("003", "王五", 17)
Student.get_stu_count()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
在类方法中是不能访问实例变量的,因为没有传递self参数。
在实例方法中是可以访问类变量的,因为是通过类名访问的。
执行结果:
一共创建了3个学生
# 8 推荐的使用方式
实例变量和实例方法推荐使用 对象.变量 和 对象.方法() 来调用的。
类变量和类方法推荐使用 类.变量 和 类.方法() 来调用。
不过通过 对象.变量 也是可以访问类变量的,只是不推荐。
查看下面的代码:
class Student:
stu_count = 0;
def __init__(self, sid, name, age):
self.sid = sid # 学号
self.name = name # 姓名
self.age = age # 年龄
Student.stu_count += 1
stu1 = Student("001", "张三", 18)
print(stu1.stu_count) # 结果为1,访问的是类变量
stu1.stu_count = 10
print(stu1.stu_count) # 结果为10,访问的是成员变量
print(Student.stu_count) # 结果还是1,访问的是类变量
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
执行结果:
1 10 1
第一次执行 print(stu1.stu_count) 的时候,是使用对象调用了类变量 stu_count,所以执行结果是1;
当执行stu1.stu_count = 10 的时候,是给对象stu1添加了一个实例变量,并不是访问类变量,所以这个时候stu1是多了一个实例变量 stu_count,所以再次执行 print(stu1.stu_count) 的时候,执行结果是10;
此时执行 print(Student.stu_count),访问的是类变量 stu_count, 执行结果为1。
通过 对象.变量 = 值 的方式给对象的属性赋值,如果该对象没有该属性,就会给该对象添加相应的属性。所以我们之前在 init 构造方法中创建实例变量是一种推荐的方式,其实在任何地方,通过 对象.变量 = 值,都可以给对象创建实例变量,只是在类本身中,对象.变量 = 值 可以写成 self.变量 = 值,所以在类的其他方法中也可以通过self.变量 = 值 为对象创建实例变量。
但是我们推荐在 __init__构造方法中为对象创建实例变量。
# 9 静态方法
静态方法的作用是用来定义一些工具类函数。
在静态方法中不能访问实例成员和类成员。
使用 @staticmethod 注解来创建静态方法。
举个栗子:
我们可以定义数学运算的工具类,类中的方法可以通过类名来访问。
class Math_Util:
@staticmethod
def get_max(a, b): # 获取大的数
return a if a > b else b
@staticmethod
def get_min(a, b): # 获取小的数
return a if a < b else b
max_num = Math_Util.get_max(11, 15)
print(max_num)
min_num = Math_Util.get_min(11, 15)
print(min_num)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
执行结果:
15
11
# 10 类的内置方法
上面说的__init__ 构造方法,是Python类内置的方法之一,Python类有很多内置的方法,这些内置方法我们称之为:魔术方法。
下面介绍几个常用的类内置方法。
# 1 __str__
__str__的方法的作用是将对象转换为字符串。
当我们直接打印对象,或将对象转换为字符串进行打印的时候,会显示地址信息。
举个栗子:
class Student:
def __init__(self, sid, name, age):
self.sid = sid
self.name = name
self.age = age
stu = Student("001", "张三", 18)
print(stu)
print(str(stu))
2
3
4
5
6
7
8
9
10
11
执行结果:
<main.Student object at 0x100498bd0> <main.Student object at 0x100498bd0>
这些地址信息对于我们而言,不太关注,我们希望打印对象相关的信息,那么可以重写 __str__ 内置方法,自定义输出的内容:
class Student:
def __init__(self, sid, name, age):
self.sid = sid
self.name = name
self.age = age
def __str__(self):
return f"sid:{self.sid}, name:{self.name}, age:{self.age}"
stu = Student("001", "张三", 18)
print(stu)
print(str(stu))
2
3
4
5
6
7
8
9
10
11
12
13
14
执行结果:
sid:001, name:张三, age:18 sid:001, name:张三, age:18
# 2 __lt__
两个对象是无法进行比较大小的,但是通过重写 __lt__方法,来对两个对象进行比较,可以实现两个对象大于和小于的比较。
class Student:
def __init__(self, sid, name, age):
self.sid = sid
self.name = name
self.age = age
def __lt__(self, other): # other表示另一个对象,返回值为True或Flase
return self.age < other.age
stu1 = Student("001", "张三", 18)
stu2 = Student("002", "李四", 19)
print(stu1 > stu2)
2
3
4
5
6
7
8
9
10
11
12
13
14
通过重写 __lt__ 方法,可以指定两个对象比较大小的判断方式。
其实还有一个 __gt__ 的方法,是大于符号的魔术方法,但是实现了 __lt__ 方法能同时比较大于和小于,所以就 __gt__ 就没必要实现了,两个实现一个就可以了。
# 3 __le__
__le__ 是 <= 的魔术方法,通过实现 __le__ 方法, 可以实现两个对象大于等于和小于等于的比较。
class Student:
def __init__(self, sid, name, age):
self.sid = sid
self.name = name
self.age = age
def __le__(self, other): # other表示另一个对象,返回值为True或Flase
return self.age <= other.age
stu1 = Student("001", "张三", 18)
stu2 = Student("002", "李四", 19)
print(stu1 <= stu2)
2
3
4
5
6
7
8
9
10
11
12
13
14
同样,>= 的魔术方法是 __ge__ ,不过 __le__和 __ge__ 实现一个就可以了。
# 4 __eq__
不实现__eq__ 方法,两个对象也是可以进行等于比较的,但是是比较两个对象的内存地址,两个不同的对象==比较一定是Flase。
如果实现了__eq__方法,就可以按照自己的想法来判断两个对象是否相等。
class Student:
def __init__(self, sid, name, age):
self.sid = sid
self.name = name
self.age = age
def __eq__(self, other): # other表示另一个对象,返回值为True或Flase
return self.age == other.age
stu1 = Student("001", "张三", 18)
stu2 = Student("002", "李四", 18)
print(stu1 == stu2)
2
3
4
5
6
7
8
9
10
11
12
13
14
上面实现了__eq__方法,通过年龄来判断两个对象是否相等。
# 5 __repr__
__repr__ 方法的作用是将对象转换为字符串。怎么和 __str__ 方法一样?
编写代码:
class Student:
def __init__(self, sid, name, age):
self.sid = sid
self.name = name
self.age = age
def __repr__(self):
return f"sid:{self.sid}, name:{self.name}, age:{self.age}"
stu = Student("001", "张三", 18)
print(stu)
print(str(stu))
2
3
4
5
6
7
8
9
10
11
12
13
14
执行结果:
sid:001, name:张三, age:18 sid:001, name:张三, age:18
真的和 __str__ 方法一样?
__repr__ 方法如果只是用来打印对象信息,那么和 __str__ 方法一样,但是__repr__ 方法更重要的是转换为解释器可识别的字符串。
需要搭配 eval() 函数才能显示其功能。
先介绍一下 eval() 函数。
举个栗子:
str = "1 + 2 * 3"
result = eval(str)
print(result) # 执行结果:7
2
3
看出 eval() 函数的牛逼之处了吗?它将字符串作为代码执行了。
下面通过 __repr__ 方法和 eval 函数克隆对象:
首先 __repr__ 方法返回的字符串是可以执行的python语句,需要和 __init__ 构造方法一致,这样后面才能通过 eval 函数来执行这个语句,然后调用构造方法创建对象。
class Student:
def __init__(self, sid, name, age):
self.sid = sid
self.name = name
self.age = age
def __repr__(self):
return f"Student('{self.sid}', '{self.name}', {self.age})"
stu1 = Student("001", "张三", 18)
stu_str = repr(stu1) # 获取__repr__()方法返回的string数据
print(stu_str)
stu2 = eval(stu_str) # 将string执行,返回的是一个对象,相当于克隆了一个对象
print(stu2.name)
print(stu1 == stu2)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 7.2 封装
面向对象编程,是一种编程思想,简单的理解就是:先有模板,也就是类,根据模板去创建实例,也就是对象,然后使用对象来完成功能开发。
我们经常说面向过程编程和面向对象编程,面向过程编程关注的是实现功能的步骤,面向对象编程更关注的是谁来实现功能。
面向对象编程有3大特性:
- 封装
- 继承
- 多态
下面依次开始讲起。
在前面我们创建类,在类中定义了属性和方法,通过属性和方法来对现实世界的事物进行抽象的描述。
一个事物有很多的属性和方法,但是并不是所有属性和方法都需要开放出来。例如我们定义了一个手机类,我们可以使用手机打电话、拍照等,但是我们并不关心手机电压,驱动信息,也不关心内存的分配,CPU的调度等,虽然这些都属于手机的属性和行为。
我们可以将用户不关心的属性和方法封装并隐藏起来,只给类内部的方法调用,例如上网会用到4G模块,但是不是由用户来使用4G模块,而是由手机上网的功能开调用4G模块,只开放用户直接使用的信息和功能。
那么回过头来看,什么是封装?
它指的是将对象的状态信息隐藏在对象内部,不允许外部程序直接访问对象的内部信息。如果要访问这些信息,需要通过该类所提供的方法来实现对内部信息的操作和访问。
# 1 私有属性和方法
那么怎么将不想暴露的变量和方法隐藏起来呢,就需要用到私有成员变量和私有成员方法。
定义私有成员的方式:
- 定义私有成员变量:变量名以 __开头,2个下划线开头
- 定义私有成员方法:方法名以 __开头,2个下划线开头
举个栗子:
class Phone:
def __init__(self):
self.producer = "华为" # 手机品牌
self.__voltage = 12 # 电压
def call(self):
print("打电话")
print(f"手机品牌:{self.producer}")
print(f"手机电压:{self.__voltage}")
# 定义一个私有方法
def __get_run_voltage(self):
print(f"当前电压:{self.__voltage}")
phone = Phone()
phone.call()
phone.producer = "小米"
phone.__voltage = 24 # 这里修改的不是私有属性的值
print(phone.producer)
print(phone.__voltage) # 这里访问的不是私有属性
phone.call()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
如果不想暴露的属性和方法可以定义为私有成员。私有属性和私有方法只能在类内部的方法中调用,不能通过对象来调用。
上面的代码 phone.__voltage = 24, 并不能修改私有属性的值,而是给对象添加了一个额外的属性。
执行结果:
打电话 手机品牌:华为 手机电压:12 小米 24 打电话 手机品牌:小米 手机电压:12
# 2 骗人的私有属性
我们上面私有属性和方法在类外部无法调用,只能在类内部使用,但这其实是一个障眼法的。
查看下面的代码:
class Phone:
def __init__(self):
self.producer = "华为" # 手机品牌
self.__voltage = 12 # 电压
def call(self):
print("打电话")
print(f"手机品牌:{self.producer}")
print(f"手机电压:{self.__voltage}")
# 定义一个私有方法
def __get_run_voltage(self):
print(f"当前电压:{self.__voltage}")
phone = Phone()
print(phone.__dict__) # 将对象属性以字典的形式输出
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
将对象以字典的形式输出,查看一下对象的结构。
执行结果:
{'producer': '华为', '_Phone__voltage': 12}
哦,哦,私有属性__voltage 变成了 _Phone__voltage 。那么我们能否修改属性 _Phone__voltage 来修改私有属性呢?
代码验证一下:
class Phone:
def __init__(self):
self.producer = "华为" # 手机品牌
self.__voltage = 12 # 电压
def call(self):
print("打电话")
print(f"手机品牌:{self.producer}")
print(f"手机电压:{self.__voltage}")
# 定义一个私有方法
def __get_run_voltage(self):
print(f"当前电压:{self.__voltage}")
phone = Phone()
phone._Phone__voltage = 24 # 修改私有属性
phone.call()
phone._Phone__get_run_voltage() # 调用私有方法
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
执行结果:
打电话 手机品牌:华为 手机电压:24 当前电压:24
所以,私有属性和私有方法是骗人的障眼法,完全可以通过 _类型__私有属性 和 _类型__私有方法 的形式来调用。
但是,这是一个君子约定,非常不建议这么做。
# 3 封装的进阶
我们前面说到,封装是将对象的状态信息隐藏在对象内部,不允许外部程序直接访问对象的内部信息。如果要访问这些信息,需要通过该类所提供的方法来实现对内部信息的操作和访问。
在面向对象编程思想中,我们一般会将所有的属性都设置为私有的,然后为每个属性提供两个对应的方法,分别用来获取和设置对应的属性,这两个方法称为getter和setter方法,在java中就是这么做的。
举个栗子:
class Phone:
def __init__(self, producer, voltage):
self.__producer = producer # 手机品牌
self.__voltage = voltage # 电压
def get_producer(self):
return self.__producer
def set_producer(self, producer):
self.__producer = producer
def get_voltage(self):
return self.__voltage
def set_voltage(self, voltage):
if voltage < 36:
self.__voltage = voltage
else:
raise ValueError("参数错误") # 限制传入的参数值,进行报错处理
phone = Phone("华为", 12)
print(phone.get_producer()) # 通过getter方法获取变量
print(phone.get_voltage())
phone.set_producer("小米") # 通过setter方法设置变量
phone.set_voltage(24)
print(phone.get_producer())
print(phone.get_voltage())
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
这样做的话,严格控制了属性获取和设置的入口,如果通过 对象.属性 来修改,代码很多的时候完全会不知道在哪里修改了属性导致出现了问题。另外我们可以在setter方法中对属性的设置进行限制。
执行结果:
华为 12 小米 24
# 4 getter和setter的初级进化
上面通过getter和setter方法来获取或设置属性显得略显复杂,有没有更好的方式呢?
肯定有的,不然还在这里哔哔?
直接上代码:
class Phone:
def __init__(self, producer, voltage):
self.producer = producer # 访问的不是属性,是方法
self.voltage = voltage # 访问的不是属性,是方法
def get_producer(self):
return f"品牌:{self.__producer}"
def set_producer(self, producer):
print(f"设置producer:{producer}")
self.__producer = producer
def get_voltage(self):
return f"电压:{self.__voltage}"
def set_voltage(self, voltage):
print(f"设置voltage:{voltage}")
if voltage < 36:
self.__voltage = voltage
else:
raise ValueError("参数错误") # 限制传入的参数值,进行报错处理
producer = property(get_producer, set_producer)
voltage = property(get_voltage, set_voltage)
phone = Phone("华为", 12)
print(phone.producer)
print(phone.voltage)
phone.producer = "小米"
phone.voltage = 24
print(phone.producer)
print(phone.voltage)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
我们在之前的代码上添加了两行代码:
producer = property(get_producer, set_producer)
voltage = property(get_voltage, set_voltage)
2
这是给属性绑定了getter和setter方法,这样,在访问属性的时候,会直接调用getter和setter方法。
所以 self.producer 和 phone.producer 都是调用的是方法,而不是属性,通过执行结果可以看出来,或者通过断点调试。
执行结果:
设置producer:华为 设置voltage:12 品牌:华为 电压:12 设置producer:小米 设置voltage:24 品牌:小米 电压:24
# 5 getter和setter的终极写法
上面的getter和setter的写法有些繁琐,我们还可以使用 @property 注解进一步的优化。
代码如下:
class Phone:
def __init__(self, producer, voltage):
self.producer = producer # 访问的不是属性,是方法
self.voltage = voltage # 访问的不是属性,是方法
@property
def producer(self):
return self.__producer
@producer.setter
def producer(self, producer):
self.__producer = producer
@property
def voltage(self):
return self.__voltage
@voltage.setter
def voltage(self, voltage):
if voltage < 36:
self.__voltage = voltage
else:
raise ValueError("参数错误") # 限制传入的参数值,进行报错处理
phone = Phone("华为", 12)
print(phone.producer) # 调用的是方法,不是属性
print(phone.voltage)
phone.producer = "小米" # 调用的是方法,不是属性
phone.voltage = 24
print(phone.producer)
print(phone.voltage)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
每个属性对应两个与属性名相同的方法,分别用于获取和设置属性,并在方法上添加 @property 和 @属性.setter 注解。
执行结果:
华为 12 小米 24
如果想要属性是只读的,可以将setter删掉。
其实在Python中,我们有时候也没有必要针对所有属性都添加getter和setter,如果哪个属性有相关的需要,我们可以在添加,不论是否添加getter和setter,调用的代码是不变的,都是 对象.属性 ,只是有getter和setter,调用的是方法。
# 6 __slots__
我们之前可以通过 对象.属性 = 值 随时为一个对象添加属性。
__slots__ 的作用就是限制一个类创建的实例只能有固定的属性,不能随意添加属性。
举个栗子:
class Phone:
__slots__ = ("producer", "__voltage")
def __init__(self, producer, voltage):
self.producer = producer
self.__voltage = voltage
phone = Phone("华为", 12)
phone.size = 6 # 报错:AttributeError: 'Phone' object has no attribute 'size'
2
3
4
5
6
7
8
9
10
11
上面的类只能包含属性 __slots__ 指定的属性,添加别的属性就会报错。
优点:防止写错了属性名字而新增了新的属性,导致程序出现bug。
缺点:运行时不能为对象添加属性了,丧失了动态语言的灵活性。
这个功能可能这辈子也用不到,但是还是知道一下。
# 7.3 继承
在现实世界,有麻雀和鸽子,它们都属于鸟类,麻雀、鸽子和鸟类的关系是父类和子类的关系。
麻雀和鸽子都会飞,我们可以在麻雀类中定义一个飞的方法,在鸽子类中定义一个飞的方法,但是这两个飞的方法是一样的,都是用翅膀飞。我们可以在鸟类中定义一个飞的方法,让麻雀和鸽子类都继承这个鸟类,那么它们就拥有了飞的方法,就不用再定义了。
继承分为单继承和多继承:
单继承:一个类只继承一个父类
多继承:一个类继承多个父类
# 1 单继承
单继承的语法:
class 类名(父类名):
类内容
2
麻雀继承鸟类,鸽子继承鸟类,都属于单继承,演示一下:
class Bird: # 定义一个鸟类
age = None # 鸟都有年龄
def fly(self): # 定义了一个飞的方法
print(f"我{self.age}岁了,我会飞")
def tweet(self): # 定义了一个叫的方法
print("我会叫")
class Sparrow(Bird): # 定义一个麻雀类,继承自鸟类
pass
class Pigeon(Bird): # 定义一个鸽子类,继承自鸟类
pass
sparrow = Sparrow() # 创建一个麻雀对象
sparrow.age = 1
sparrow.fly()
sparrow.tweet()
pigeon = Pigeon() # 创建一个鸽子对象
pigeon.age = 2
pigeon.fly()
pigeon.tweet()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
在上面的代码中,我们先定义了一个鸟类,然后在鸟类中定义了 age属性 ,并定义了两个方法 fly方法和 tweet方法;
然后定义类麻雀类,继承鸟类,那么就拥有了鸟类的属性和方法。鸽子类也同样。
执行结果:
我1岁了,我会飞 我会叫 我2岁了,我会飞 我会叫
注意,继承不能继承父类私有的成员变量和方法。
如果父类的成员变量和属性不想被子类继承,可以设置为私有成员。
# 2 复写父类方法
所以继承父类就拥有了父类非私有的成员变量和方法,如果父类不是我想要的方法,我还可以进行覆盖。
例如,鸟类提供了叫的方法,但是我麻雀有自己的叫法,我要啾啾叫,那么我们可以重写父类的方法,实现自己的个性化。
class Bird: # 定义一个鸟类
age = None # 鸟都有年龄
def fly(self): # 定义了一个飞的方法
print(f"我{self.age}岁了,我会飞")
def tweet(self): # 定义了一个叫的方法
print("我会叫")
class Sparrow(Bird): # 定义一个麻雀类,继承自鸟类
pass
class Pigeon(Bird): # 定义一个鸽子类,继承自鸟类
def tweet(self): # 重写了父类叫的方法
print("我会咕咕叫")
sparrow = Sparrow() # 创建一个麻雀对象
sparrow.age = 1
sparrow.fly()
sparrow.tweet()
pigeon = Pigeon() # 创建一个鸽子对象
pigeon.age = 2
pigeon.fly()
pigeon.tweet()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
执行结果:
我1岁了,我会飞 我会叫 我2岁了,我会飞 我会咕咕叫
# 3 调用父类方法
我们在重写父类方法的时候,应该尽量做到在父类方法的基础上进行扩展。
所以很有可能需要调用父类被重写的方法,然后在父类原来的方法上进行扩展。
那么如果我们想要在子类中调用父类被重写的属性和方法呢?
有两种方式:
方式一:
super().成员变量
super().成员方法
2
方式二:
父类名.成员变量
父类名.成员方法(self)
2
举个栗子:
class Bird: # 定义一个鸟类
age = 1
def tweet(self): # 定义了一个叫的方法
print("我会啾啾叫")
class Pigeon(Bird): # 定义一个鸽子类,继承自鸟类
age = 3
def tweet(self): # 重写了父类叫的方法
print("我会咕咕叫")
def test(self):
print(f"age:{Bird.age}") # 调用父类的成员
Bird.tweet(self)
print(f"age:{super().age}") # 调用父类的成员
super().tweet()
print(f"age:{self.age}")
self.tweet()
pigeon = Pigeon() # 创建一个鸽子对象
pigeon.age = 10
pigeon.test()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
执行结果:
age:1 我会啾啾叫 age:1 我会啾啾叫 age:10 我会咕咕叫
# 4 继承的构造方法
子类继承父类,如果子类没有构造方法,则会使用父类的。
举个栗子:
class Bird:
age = None
def __init__(self, age):
self.age = age
class Pigeon(Bird):
pass
pigeon = Pigeon() # 创建对象,没有传入参数
print(pigeon.age)
2
3
4
5
6
7
8
9
10
11
12
13
上面创建对象,没有传入参数,所以在运行的时候报错,因为没有构造方法,会使用父类的,父类的构造方法是需要传入参数的。
子类若有构造方法,则子类的构造方法必须先调用父类的构造函数。
class Bird:
age = None
def __init__(self, age):
self.age = age
class Pigeon(Bird):
def __init__(self, name, age):
super().__init__(age) # 调用父类的构造方法
self.name = name
pigeon = Pigeon("鸽子", 3)
print(pigeon.age)
print(pigeon.name)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
推荐上面这么做,即使你在子类的构造方法中可以这么写:
def __init__(self, name, age):
self.age = age
self.name = name
2
3
这样代码 self.age = age 和父类中的重复了,不推荐。
# 5 类型判断
我们可以判断某个对象的类型,以及是否是某个对象的实例。
首先有如下代码:
# 麻雀类和鸽子类都继承自鸟类。
class Bird: # 鸟类
pass
class Sparrow(Bird): # 麻雀类,继承自鸟类
pass
class Pigeon(Bird): # 鸽子类,继承自鸟类
pass
2
3
4
5
6
7
8
9
10
11
12
# type() 函数
type()函数可以判断某个对象是否是某个类型,注意:子类的对象不是父类的对象的类型。
举个栗子,基于上面的代码:
pigeon = Pigeon()
sparrow = Sparrow()
print(type(pigeon) == Pigeon) # True,鸽子对象的类型是鸽子
print(type(pigeon) == Bird) # False,鸽子对象的类型不是鸟
2
3
4
5
# isinstance()函数
isinstance()函数可以判断某个对象是否是某个类型的实例,子类对象也是父类对象的实例。
举个例子,基于上面的代码:
pigeon = Pigeon()
sparrow = Sparrow()
print(isinstance(pigeon, Pigeon)) # True,鸽子对象是鸽子类的实例
print(isinstance(pigeon, Bird)) # True,鸽子对象是鸟类的实例
print(isinstance(sparrow, Pigeon)) # False,鸽子对象不是麻雀类的实例
2
3
4
5
6
# issubclass()函数
issubclass()函数可以用来判断一个类是否是另外一个类的子类。
举个栗子,基于上面的代码:
pigeon = Pigeon()
sparrow = Sparrow()
print(issubclass(Pigeon, Bird)) # True,鸽子类是鸟类的子类
print(issubclass(Pigeon, Sparrow)) # False,鸽子类不是麻雀类的子类
2
3
4
5
# 6 多继承
我现在是一只鸡,我也想继承鸟类,但是我是家禽,我还想继承家禽类。
那么就需要用到多继承。
多继承的语法:
class 类名(父类1, 父类2, ..., 父类N):
类内容
2
举个栗子:
class Bird: # 定义一个鸟类
age = None # 鸟都有年龄
def fly(self): # 定义了一个飞的方法
print(f"我{self.age}岁了,我会飞")
class Poultry: # 定义一个家禽类
number = None # 家禽需要编号
def eat(self): # 定义了一个吃的方法
print("我吃饭啦")
class Chicken(Bird, Poultry): # 定义一个鸡类,继承自鸟类和家禽类
def fly(self):
print("我不会飞")
chicken = Chicken() # 创建一个鸡对象
chicken.age = 1
chicken.number = 9527
chicken.fly()
chicken.eat()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
定义了一个鸡类,继承鸟类和家禽类,那么这个鸡类就拥有了鸟类和家禽类的属性和方法。
执行结果:
我不会飞 我吃饭啦
# 多继承的解析顺序
如果继承的多个父类拥有同样的属性和方法,那么会使用哪个父类的呢?
会使用先继承的父类的,后继承的无效,如果父类中都没有,则会去父类的父类寻找,一直向上找。
即使类没有写明继承其他类,但是所有的类都直接或间接继承自Object类。
演示一下:
class Bird: # 定义一个鸟类
age = 1
def eat(self):
print("我去觅食")
class Poultry: # 定义一个家禽类
number = None
age = 3
def eat(self):
print("我开饭啦")
class Chicken(Bird, Poultry): # 定义一个鸡类,继承自鸟类和家禽类
pass
chicken = Chicken() # 创建一个鸡对象
print(chicken.age)
chicken.eat()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
因为先继承鸟类,所以是继承鸟类的成员属性和方法。
执行结果:
1 我去觅食
我们还可以通过类的mro()方法,查看父类方法的解析顺序:
例如类D继承类B、C,类B、C继承A。
class A:
def test(self):
print("A")
class B(A):
def test(self):
print("B")
class C(A):
def test(self):
print("C")
class D(B, C):
pass
d = D()
d.test()
print(D.mro())
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
执行结果:
B [<class 'main.D'>, <class 'main.B'>, <class 'main.C'>, <class 'main.A'>, <class 'object'>]
通过mro()方法可以查到类方法的解析顺序,也就是先找D,再找B,然后找C,再找A,最终找到Object类。
如果此时想调用其他父类的函数呢?
可是使用 父类名.方法名(self, 参数),例如我们在D类中,添加一个方法来调用:
class D(B, C):
def fun(self):
self.test() # 默认调用的是B类的test()方法
C.test(self) # 调用C类的test()方法
2
3
4
# 7.4 多态
# 1 什么是多态
多态就是多种状态,同一个类型的父类型对象,因为指向的是不同的子对象,而表现出的不同的状态。
所以多态是建立在继承的基础之上的。
举个栗子:
class Bird:
def tweet(self):
pass
class Sparrow(Bird):
def tweet(self):
print("我会啾啾叫")
class Pigeon(Bird):
def tweet(self):
print("我会咕咕叫")
def bird_tweet(bird: Bird):
bird.tweet()
sparrow = Sparrow() # 创建一个麻雀对象
pigeon = Pigeon() # 创建一个鸽子对象
bird_tweet(sparrow)
bird_tweet(pigeon)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
上面麻雀类和鸽子类都继承自鸟类,这里还定义了一个函数 bird_tweet,函数的参数是鸟对象,在函数中,调用鸟类的叫方法。
然后创建了一个麻雀对象和鸽子对象,调用 bird_tweet 函数,分别传入麻雀对象和鸽子对象。
执行结果:
我会啾啾叫 我会咕咕叫
bird_tweet 函数接收的是鸟类对象,执行的都是tweet()方法,但是因为是不同的子类对象,却得到不同的结果。
以父类做定义声明,以子类做实际的工作,用于获取同一个行为的不同状态,这就是多态。
那也没看出多态有什么用啊。
多态的作用:
- 提高代码的维护性
- 提高代码的扩展性
- 把不同的子类对象当做父类来看待,可以屏蔽不同子类对象之间的差异,写出通用的代码,以适应需求的不断变化。
# 2 多态的使用
说了那么多,有点虚,举个栗子:
实现一个功能:学生做交通工具去某个地方,交通工具可能是汽车、飞机。
先定一个汽车类:
class Car:
def run(self, destination):
print(f"开车去->{destination}")
2
3
再定义一个飞机类:
class Plane:
def fly(self, destination):
print(f"飞去->{destination}")
2
3
然后定义一个学生类:
class Student:
def go_to(self, vehicle, destination):
if type(vehicle) == Car:
vehicle.run(destination)
elif type(vehicle) == Plane:
vehicle.fly(destination)
2
3
4
5
6
7
学生类有一个go_to()方法,接收交通工具和目的地,然后在方法中判断交通工具的类型,然后调用交通工具的方法。
调用代码:
stu = Student()
car = Car()
plane = Plane()
stu.go_to(car, "北京")
stu.go_to(plane, "新疆")
2
3
4
5
执行结果:
开车去->北京 飞去->新疆
上面的代码可以实现功能,但是不易于扩展,如果我们现在增加一个交通工具火车,则还需要修改Student类的go_to()方法,针对新的交通工具来处理,因为学生类和汽车、飞机类直接存在依赖关系,耦合性高。
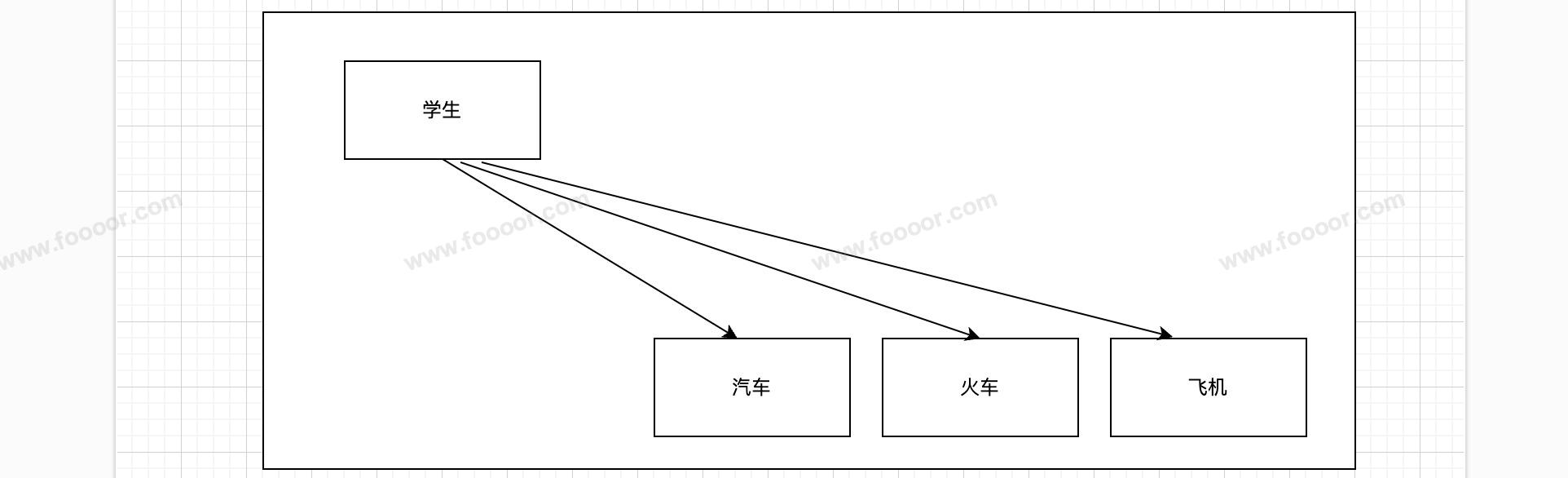
这样是违反了设计原则中的开闭原则,对扩展是开放的,对修改是封闭的,也就是允许在不改变它代码的前提下变更它的行为。
所以上面的代码扩展性就比较差了,那么怎么来优化代码,降低代码的耦合性呢?
这就需要用到多态了。
首先定义一个父类Vehicle(交通工具类),并定义一个transport()方法,都是交通工具,都是运输功能嘛。
然后让Car类和Plane类都继承这个父类,因为不同的子类运输方式不一样,所以子类需要重写父类的方法,实现自己的功能。
class Vehicle:
def transport(self, destination):
pass
class Car:
def transport(self, destination):
print(f"开车去->{destination}")
class Plane:
def transport(self, destination):
print(f"飞去->{destination}")
2
3
4
5
6
7
8
9
10
11
然后修改学生类:
class Student:
def go_to(self, vehicle, destination):
vehicle.transport(destination)
2
3
4
学生类只需要调用交通工具的运输功能就可以了。
调用的代码不变:
stu = Student()
car = Car()
plane = Plane()
stu.go_to(car, "北京")
stu.go_to(plane, "新疆")
2
3
4
5
执行结果:
开车去->北京 飞去->新疆
上面的代码使用了多态,学生类与各个交通工具子类已经不直接产生关系,遵从了设置原则中的依赖倒置原则(程序依赖于抽象接口,不要依赖于具体实现)。
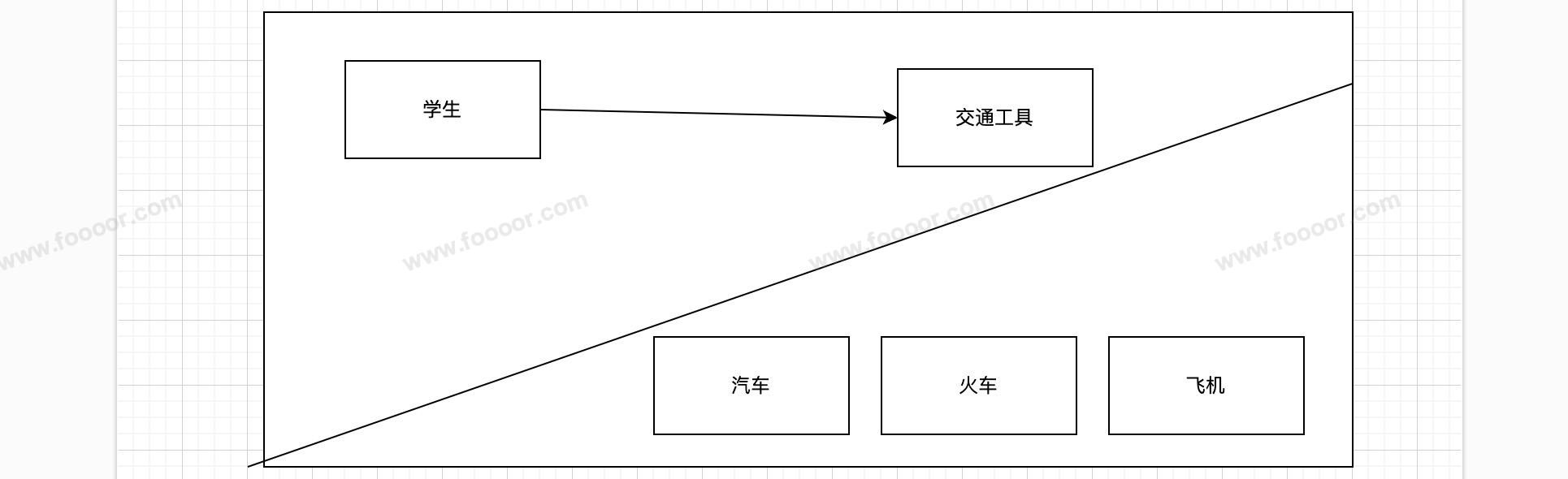
此时如果新增一个火车的交通工具,不用再修改学生类的代码,代码耦合性大大降低。
# 3 抽象类
什么是抽象类?
含有抽象方法的类成为抽象类。
那什么是抽象方法?
抽象方法就是没有方法体,方法体为空的方法。
上面的Vehicle类就是一个抽象类。
class Vehicle:
def transport(self, destination):
pass
2
3
抽象类有什么作用呢?
一般抽象类都是作为父类使用的,父类用来确定有哪些方法,相当于用来确定设计的标准,用于对子类的约束。
子类用来实现父类的标准,负责具体的实现,配合多态使用,获得不同的工作状态。
# 7.5 类与类的关系
类与类有以下几种关系:
泛化
子类与父类的关系,B类泛化A类,B类是A类的一种。
场景:B类继承A类。
关联
部分与整体的关系,A与B关联,B是A的一部分。
场景:在A类中包含B类型的属性。
依赖
合作关系,A类依赖B类,A的某些功能需要靠B类实现。
场景:B类型作为A类中方法的参数,并不是A的成员。
# 7.6 数据与JSON的转换
# 1 JSON 简介
什么是JSON?
JSON就是特定格式的字符串。我们可以将数据按照这个格式进行封装,然后可以在不同的语言和系统之间进行传送和交互。
JSON的2种格式:
格式一:
是一个对象格式的结构。{} 括起来,其中是属性。
{
key1:value1,
key2:value2,
...
}
2
3
4
5
举个栗子,以下是一个学生信息的JSON格式,和Python中的字典格式是一样的:
{
"sid": "001",
"name": "zhangsan",
"age": 18
}
2
3
4
5
格式二:
外部是一个列表格式的结构,内部是一个个的对象格式的数据。
[
{
key1:value1,
key2:value2
},
{
key3:value3,
key4:value4
}
]
2
3
4
5
6
7
8
9
10
举个栗子,以下是一个学生信息的列表
[{
"sid": "S001",
"name": "zhangsan",
"age": 18
},
{
"sid": "S002",
"name": "lisi",
"age": 19
},
{
"sid": "S003",
"name": "wangwu",
"age": 17
}
]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
在Python中,字典和JSON数据可以无缝切换。
将字典转换为JSON数据
import json
stu_dict = {"sid": "001", "name": "zhangsan", "age": 18}
json_data = json.dumps(stu_dict, ensure_ascii=False) # 使用dumps()方法,将字典转换为JSON数据
print(json_data)
print(type(json_data)) # 类型为字符串
2
3
4
5
6
7
执行结果:
{"sid": "001", "name": "zhangsan", "age": 18} <class 'str'>
如果有中文,需要添加参数ensure_ascii=False。
将JSON数据转换为字典
import json
json_data = '{"sid": "001", "name": "张三", "age": 18}'
stu_dict = json.loads(json_data) # 使用loads()方法,将JSON数据转换为字典
print(stu_dict["name"])
2
3
4
5
6
执行结果:
张三
# 2 对象转JSON
对象转换为JSON
import json # 导入json模块
class Student:
def __init__(self, sid, name, age):
self.sid = sid
self.name = name
self.age = age
stu = Student("001", "张三", 98)
stu_json = json.dumps(stu)
print(f"对象转换为json:{stu_json}")
2
3
4
5
6
7
8
9
10
11
12
在运行的时候会报错:TypeError: Object of type Student is not JSON serializable ,这是因为没有提供序列化的方法。
我们需要先获取对象的字典格式的数据:
import json # 导入json模块
class Student:
def __init__(self, sid, name, age):
self.sid = sid
self.name = name
self.age = age
stu = Student("001", "张三", 98)
stu_json = json.dumps(stu.__dict__, ensure_ascii=False) # 获取对象的字典格式
print(stu_json)
2
3
4
5
6
7
8
9
10
11
12
13
14
执行结果:
{"sid": "001", "name": "张三", "age": 98}
上面的写法有一个缺点,就是没法针对对象的属性值做特殊的处理,例如我们下面在对象中添加了一个时间的属性,然后输出JSON的时候,想按照指定的格式输出时间,则就需要对时间属性进行处理,此时就需要添加一个方法,返回对象的字典结构数据,在方法中对时间进行处理。
import json # 导入json模块
import time # 导入time模块
class Student:
def __init__(self, sid, name, age):
self.sid = sid
self.name = name
self.age = age
self.time = time.time()
def to_json_dict(self): # 提供一个方法将对象转换为字典格式
return {
"sid": self.sid,
"name": self.name,
"age": self.age,
"time": time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(self.time))
}
stu = Student("001", "张三", 98)
stu_json = json.dumps(stu.to_json_dict(), ensure_ascii=False)
print(stu_json)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
执行结果:
{"sid": "001", "name": "张三", "age": 98, "time": "2023-03-28 21:43:54"}
列表转换为JSON
import json # 导入json模块
import time
class Student:
def __init__(self, sid, name, age):
self.sid = sid
self.name = name
self.age = age
self.time = time.time()
def to_json_dict(self): # 提供一个方法将对象转换为字典格式
return {
"sid": self.sid,
"name": self.name,
"age": self.age,
"time": time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(self.time))
}
stu_list = [Student("001", "张三", 98), Student("002", "李四", 99)]
stu_list_json = json.dumps([stu.to_json_dict() for stu in stu_list], ensure_ascii=False)
print(stu_list_json)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
使用了 [stu.to_json_dict() for stu in stu_list] 列表推导式,将一个装着对象的列表转换为一个装着字典的列表。
执行结果:
[{"sid": "001", "name": "张三", "age": 98, "time": "2023-03-28 21:52:02"}, {"sid": "002", "name": "李四", "age": 99, "time": "2023-03-28 21:52:02"}]
# 3 JSON转对象
JSON转换为对象
使用 json.loads() 方法将 JSON 字符串转换为对象。
import json
class Student:
def __init__(self, sid, name, age):
self.sid = sid
self.name = name
self.age = age
json_str = '{"sid": "001", "name": "张三", "age": 98}'
stu_dict = json.loads(json_str) # 首先将JSON字符串转换为字典
print(stu_dict["name"])
stu = Student(**stu_dict) # 然后通过双星号字典形参传递给构造方法,创建对象
print(stu.name)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
一般将JSON转换为字典就可以获取到数据了,如果有特殊的需求,再将字典转换为对象。
执行结果:
张三
张三
JSON转换为列表
import json
class Student:
def __init__(self, sid, name, age):
self.sid = sid
self.name = name
self.age = age
json_str = '[{"sid": "001", "name": "张三", "age": 98}, {"sid": "001", "name": "李四", "age": 98}]'
stu_dict_list = json.loads(json_str) # JSON转换为列表,列表中是字典
for stu in stu_dict_list:
print(f"字典 -> sid:{stu['sid']}, name:{stu['name']}, age:{stu['age']}")
stu_list = [Student(**stu_dict) for stu_dict in stu_dict_list] # 可以通过字典创建对象
for stu in stu_list:
print(f"对象 -> sid:{stu.sid}, name:{stu.name}, age:{stu.age}")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
一般将JSON转换为字典就可以获取到数据了,如果有特殊的需求,再将字典转换为对象。
执行结果:
字典 -> sid:001, name:张三, age:98 字典 -> sid:001, name:李四, age:98 对象 -> sid:001, name:张三, age:98 对象 -> sid:001, name:李四, age:98