# MySQL教程 - 5 表操作
前面已经新建了数据库,有了数据库就可以在数据库中新建表了,然后在表中存储数据。
下面介绍表的操作,包括创建、修改、删除。
操作使用 SQL 来完成,使用客户端界面操作就不介绍了,你摸索一下就可以了,相比而言,使用客户端界面操作反而要简单一些。
# 5.1 创建表
# 1 创建表
下面创建这样一张员工表,后面用来存储数据:
| id | name | age | |
|---|---|---|---|
创建表,使用 CREATE TABLE 语句:
-- 创建员工表tb_employee
CREATE TABLE tb_employee (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(100),
age INT,
email VARCHAR(100)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
2
3
4
5
6
7
CREATE TABLE tb_employee:CREATE TABLE是建表语句,tb_employee是表的名称,自己定义,一般建议加个前缀,避免和 SQL 中的保留字同名;id INT AUTO_INCREMENT PRIMARY KEY:id表示字段(列)的名称,INT是列的数据类型,这里id设置为整形,PRIMARY KEY指定该列是主键列,也就是这个表中每一条数据,该列的值必定不能为空,且值不相同,是每一行数据的唯一标识,我们在建表的时候,可以将表中的某一必定不为空且不会重复的列作为主键列,例如用户表使用用户名作为主键列,也可以创建一列没有意义的列,专门用来做主键。AUTO_INCREMENT表示的是主键的生成策略,表示自动增长,也就是插入到这个表中的数据,不需要指定id的值,id会自动累加。你也可以不设置AUTO_INCREMENT,自己手动设置id的值,保证唯一即可。name VARCHAR(100):同样,name是字段(列)的名称,VARCHAR(100)是该列的数据类型,是字符串类型,长度为100个字节。ENGINE=InnoDB DEFAULT CHARSET=utf8mb4:设置使用的存储引擎为InnoDB,默认字符编码为utf8mb4。在 MySQL 8.0 中,默认的存储引擎就是InnoDB,InnoDB引擎支持事务,现在一般都使用这个引擎。如果不设置字符编码和排序规则,默认就是继承数据库的字符编码和排序规则。
可以使用如下命令查看 MySQL 的默认存储引擎和字符编码:
-- 查看默认存储引擎,可能会显示很多引擎,可以看到哪个是默认的
SHOW ENGINES;
-- 查看默认字符编码
SHOW VARIABLES LIKE 'character_set_server';
2
3
4
5
我们在创建表的时候,还可以进行一些设置:
-- 创建员工表tb_employee
CREATE TABLE IF NOT EXISTS tb_employee (
id INT AUTO_INCREMENT PRIMARY KEY COMMENT '员工表唯一标识符',
name VARCHAR(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '姓名' ,
age INT UNSIGNED DEFAULT 18 COMMENT '员工年龄',
email VARCHAR(100) DEFAULT NULL COMMENT '员工邮箱'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE utf8mb4_0900_ai_ci COMMENT='员工表';
2
3
4
5
6
7
IF NOT EXISTS是一个判断,判断后面的tb_employee表是否存在,不存在才创建这个表,IF NOT EXISTS可以省略,也就是不进行判断。name VARCHAR(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci:其中CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci可以单独设置某个字段的编码和排序规则,该设置要放在字段类型后面;NOT NULL表示该列的值不能为空,那么在插入数据的时候,该列必须有值,否则报错,在 约束章节 会讲;COMMENT '员工表唯一标识符':表示的是改列字段的注释,同样,后面的COMMENT='员工表'是表的注释 。age INT UNSIGNED:age INT UNSIGNED说明age是int类型,因为age是肯定大于0,所以这里使用UNSIGNED设置为无符号位的。DEFAULT 18表示默认值为18,也就是插入数据的时候,不设置该列的值,那么默认值为18;同样,下面的DEFAULT NULL表示默认值为NULL,也就是空;在 约束章节 会讲。- 最后设置表的存储引擎、字符编码、排序规则、表注释。
# 2 主键设置
上面通过 id INT AUTO_INCREMENT PRIMARY KEY 这样的方式设置 id 为主键,还可以通过下面的方式设置:
-- 创建员工表tb_employee
CREATE TABLE tb_employee (
id INT, -- 非空
name VARCHAR(100),
age INT,
email VARCHAR(100),
PRIMARY KEY (id) -- 设置主键为id
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
2
3
4
5
6
7
8
通过上面的方式,我们还可以创建由多个列组成的主键:
-- 创建员工表tb_employee
CREATE TABLE tb_employee (
id INT,
name VARCHAR(100),
age INT,
email VARCHAR(100),
PRIMARY KEY (id, name) -- 设置联合主键,由id和name共同构成
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
2
3
4
5
6
7
8
在上面的表中,由 id 和 name 共同构成主键,那么该两列的值不能为空,同时不会存在两行数据,该两列的值一样。
推荐优先使用单列主键。
# 3 常用主键生成策略
自增长(Auto Increment):上面使用的就是这种方式,Auto Increment是由数据库自动生成主键值,通常为整数类型,自动递增。这种方式简单易用,无需在代码中进行控制。但是这种方式存在局限性,在分布式场景中,在数据库集群中,多个数据库节点可能产生重复的主键值,难以保证全局唯一性。UUID (Universally Unique Identifier):这种方式是通过在代码中生成 UUID,通常使用 32 位的 UUID 来作为主键,类型位字符串,不依赖于数据库,而且全局唯一。这种方式的主键没有顺序,也就是无法通过 UUID 的值大概判断数据的插入顺序。雪花算法 (Snowflake):也是在代码中生成的,Twitter 公司提出的分布式主键生成策略,生成 64 位整数,包含时间戳、机器 ID 和序列号,适用于高并发的分布式系统。因为主键中包含时间戳,所以可以通过主键判断数据的插入顺序。这种生成策略要比前面两个稍微复杂一些,不过一些框架提供了支持,例如MyBatis-Plus。
还有一些其他的主键生成策略,当然你也可以自己编写主键的生成策略,保证主键是唯一的就可以了。
# 5.2 数据类型
在保存数据的时候,针对不同的数据,需要使用到不同的数据类型,例如整数、小数、文本、日期、文件等。关系型的数据库都提供了丰富的数据类型来支持。
上面在建表的时候,使用到了 INT(整形) 和 VARCHAR(字符串)数据类型,下面介绍一下 SQL 中的常用数据类型。
MySQL 数据库提供的数据类型主要分为:整形、浮点型、字符串、日期、二进制。
# 1 整形
MySQL 的整型有符号(默认)和无符号(使用 UNSIGNED 关键字),无符号类型(UNSIGNED)不能存储负数,因此其范围大约是有符号类型的一倍。
| 类型 | 存储空间 | 有符号范围 | 无符号范围 |
|---|---|---|---|
| TINYINT | 1 字节 | -128 到 127 | 0 到 255 |
| SMALLINT | 2 字节 | -32,768 到 32,767 | 0 到 65,535 |
| MEDIUMINT | 3 字节 | -8,388,608 到 8,388,607 | 0 到 16,777,215 |
| INT或INTEGER | 4 字节 | -2,147,483,648 到 2,147,483,647 | 0 到 4,294,967,295 |
| BIGINT | 8 字节 | -2^63 到 2^63 - 1 | 0 到 2^64 - 1 |
显示宽度
我们经常会看到定义整形的时候,有人使用 INT 或 INT(5) 这样的写法,这有什么区别?
在 MySQL 中 int 字段长度是 4 个字节,是固定的,所以不管是 int、int(5) 还是 int(11),字段长度就是固定的 4 个字节。
int(5) 其实是和另一个属性 zerofill 配合使用的,表示显示宽度,什么意思?
举个栗子:
创建属性的时候,如果属性指定属性使用 INT(5) 和 zerofill :
age INT(5) zerofill,
那么年龄如果是 18,查询出的数据则是 00018 ;也就是说如果该字段值的宽度小于 5 时,会自动在前面补 0 ,如果宽度大于等于 5 ,那就不需要补 0 。
从 MySQL 8.0 开始,显示宽度已被废弃,因此在新版本中,INT 和 INT(5) 完全等价。
# 2 浮点型
| 类型 | 存储空间 | 有符号范围 | 无符号范围 |
|---|---|---|---|
| FLOAT | 4 字节(单精度) | -3.402823466E+38 ~ 3.402823466E+38 | 0 ~ 3.402823466E+38 |
| DOUBLE | 8 字节(双精度) | 1.7976931348623157E+308 ~ 1.7976931348623157E+308 | 0 ~ 1.7976931348623157E+308 |
| DECIMAL | 可变(按定义存储) | 由定义的精度和范围决定 | 由定义的精度和范围决定 |
- 浮点型中,无符号中的符号位固定为
0,符号位没有被重新分配给尾数位或指数位,因此既不会增加精度,也不会扩大范围,所以无符号并不能比有符号表达更大的范围。 - DECIMAL(M, D) :M表示表示最大位数,总长度(包括小数点前和小数点后的数字);D表示小数点后的位数,默认值为
0。例如:DECIMAL(4, 2) 表示最大长度是4,小数点后2为,也就是-xx.xx到xx.xx,存储 -100 ~ 100 以内的小数。
# 3 字符串
| 类型 | 最大长度 | 存储空间 |
|---|---|---|
| CHAR(M) | 固定长度,最多 255 字符 | 固定长度,每字符占 1 字节;不足补空格 |
| VARCHAR(M) | 可变长度,最多 65,535 字节 | 实际字符长度 + 1 字节(长度 < 255)或 2 字节(长度 >= 255) |
| TINYTEXT | 最多 255 字符 | 实际存储长度 + 1 字节 |
| TEXT | 最多 65,535 字符(64KB) | 实际存储长度 + 2 字节 |
| MEDIUMTEXT | 最多 16,777,215 字符(16MB) | 实际存储长度 + 3 字节 |
| LONGTEXT | 最多 4,294,967,295 字符( 4GB) | 实际存储长度 + 4 字节,多出的字节是存储长度 |
- CHAR:存储固定长度数据,速度快,但可能浪费空间,适用于数据长度固定且较短,如身份证号、邮编、国家代码。
- VARCHAR:存储可变长度数据,节省空间,适合于存储长度较短的变长字符串。数据存储在表的行内,紧邻其他字段,因此查询速度较快(比 CHAR 慢)。
- TEXT:存储在单独的表空间中,主表只存指针,适合大字段存储,适用于不需要对字段进行排序或频繁查询操作。注意:
TEXT类型字段无法设置默认值。另外对索引支持有限,只能索引前 255 字节。
# 4 日期和时间
| 类型 | 存储空间 | 范围 | 格式 |
|---|---|---|---|
| DATE | 3 字节 | 1000-01-01 到 9999-12-31 | YYYY-MM-DD |
| DATETIME | 8 字节 | 1000-01-01 00:00:00 到 9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS |
| TIMESTAMP | 4 字节 | 1970-01-01 00:00:01 UTC 到 2038-01-19 03:14:07 UTC | YYYY-MM-DD HH:MM:SS |
| TIME | 3 字节 | -838:59:59 到 838:59:59 | HH:MM:SS |
| YEAR | 1 字节 | 1901 到 2155 | YYYY |
可以根据格式需要,选择相应的日期和时间类型,一般数据的创建和更新时间会选择使用 DATETIME。
# 5 二进制
数据库还可以存储二进制文件,可以存储文件,例如图片、音频等文件。
| 类型 | 最大长度 | 存储空间 |
|---|---|---|
| BINARY(M) | 固定长度,最多 255 字节 | 固定长度 M 字节 |
| VARBINARY(M) | 可变长度,最多 65,535 字节 | 实际长度 + 1/2 字节 |
| TINYBLOB | 最多 255 字节 | 实际长度 + 1 字节 |
| BLOB | 最多 65,535 字节 (64KB) | 实际长度 + 2 字节 |
| MEDIUMBLOB | 最多 16,777,215 字节 (16MB) | 实际长度 + 3 字节 |
| LONGBLOB | 最多 4,294,967,295 字节( 4GB) | 实际长度 + 4 字节,多出的字节是存储长度 |
- BINARY 和 VARBINARY 用于存储二进制数据,数据是存储在主表行内的。
- BLOB 类型专门用于存储大量二进制数据,如图像、音频文件等,数据是存储在独立表空间,主表存指针。
下面创建一个员工表,包含ID、工号、姓名、身份证号码、年龄、性别、工资、入职时间,则建表语句如下:
CREATE TABLE tb_employee (
id INT AUTO_INCREMENT PRIMARY KEY, -- 员工ID,自增主键
emp_number VARCHAR(16), -- 工号,使用 VARCHAR 类型,长度可变
name VARCHAR(64), -- 姓名,使用 VARCHAR 类型,长度可变
id_card CHAR(18), -- 身份证号码,使用 CHAR 类型,长度固定为 18
age TINYINT UNSIGNED, -- 年龄,使用 TINYINT UNSIGNED,确保年龄为正数
gender CHAR(3), -- 性别,使用 CHAR(3),存储汉字 "男" 或 "女"
salary DECIMAL(10, 2), -- 工资,使用 DECIMAL,存储小数
entry_time DATETIME -- 入职时间,使用 DATETIME 类型
);
2
3
4
5
6
7
8
9
10
id 设置为自动增长;
工号,这里
varchar,从1开始递增(这里为了后面演示其他的功能,这里其实设置为固定的长度也可以,根据实际需求);姓名长度不固定,使用
varchar;身份证长度固定,使用
char;年龄不能是负数,使用无符号
tinyint够用;性别使用
char存储男、女即可,一个汉字一般是3个字节;工资使用DECIMAL(10, 2),存储小数,精确到小数点后两位,金额不能使用
Float或Double,会丢失精度。你可以可以使用无符号整数(Int或Long),以分为单位,例如1.23(一块两毛三)存为 123,避免小数运算。入职时间使用
entry_time。
# 5.3 修改表
修改表包括修改表名、字段等操作。但是理想状态下,尽量合理的设计数据库表,避免对数据库表进行更新。
一般在实际的开发中,可能通过客户端软件来修改了,因为使用客户端软件修改起来很方便。
# 1 重命名表
修改表的名称,语法:
-- 修改表名
RENAME TABLE 旧表名 TO 新表名;
-- 或
RENAME TABLE 旧表名 RENAME TO 新表名;
2
3
4
5
举个栗子:
-- 例如,将 tb_employee 修改为 tb_stu
RENAME TABLE tb_employee TO tb_emp;
-- 例如,重命名多个表
RENAME TABLE tb_employee TO tb_emp, tb_department TO tb_dept;
2
3
4
5
# 2 添加字段
给表添加一个列:
语法:
-- 方括号[]中的内容可以省略,[约束]后面再讲
ALTER TABLE 表名 ADD 字段名 数据类型(长度) [comment 注释][约束];
2
举个栗子:
-- 例如,给 tb_employee 表添加 phone_number 字段
ALTER TABLE tb_employee ADD phone_number VARCHAR(32);
2
# 3 修改字段
修改数据类型,语法:
ALTER TABLE 表名 MODIFY 字段名 新数据类型(长度);
举个栗子:
-- 例如,修改 tb_employee 的 phone_number 字段为 char 类型
ALTER TABLE tb_employee MODIFY phone_number CHAR(11);
2
修改字段名和数据类型,语法:
-- 方括号[]中的内容可以省略,[约束]后面再讲
ALTER TABLE 表名 CHANGE 旧字段名 新字段名 数据类型(长度) [comment 注释][约束];
2
举个栗子:
-- 例如,修改 tb_employee 的 phone_number 字段为 mobile_phone
ALTER TABLE tb_employee CHANGE phone_number mobile_phone CHAR(11);
2
# 4 删除字段
删除表的一个列,语法:
-- 删除一列
ALTER TABLE 表名 DROP 字段名;
-- 或
ALTER TABLE 表名 DROP COLUMN 字段名;
2
3
4
举个栗子:
-- 例如,删除 tb_employee 表的 phone_number 字段
ALTER TABLE tb_employee DROP phone_number;
2
# 5.4 查询表
这里查询表不是查询表中的数据,而是查询当前使用的数据库中有哪些表。在客户端软件中,一般都会列出来数据库下有哪些表:
# 1 查看有哪些表
通过 SQL 查询当前数据库下有哪些表:
SHOW TABLES;
一般执行 SQL 语句创建表,都需要右键数据库进行刷新,才能显示。
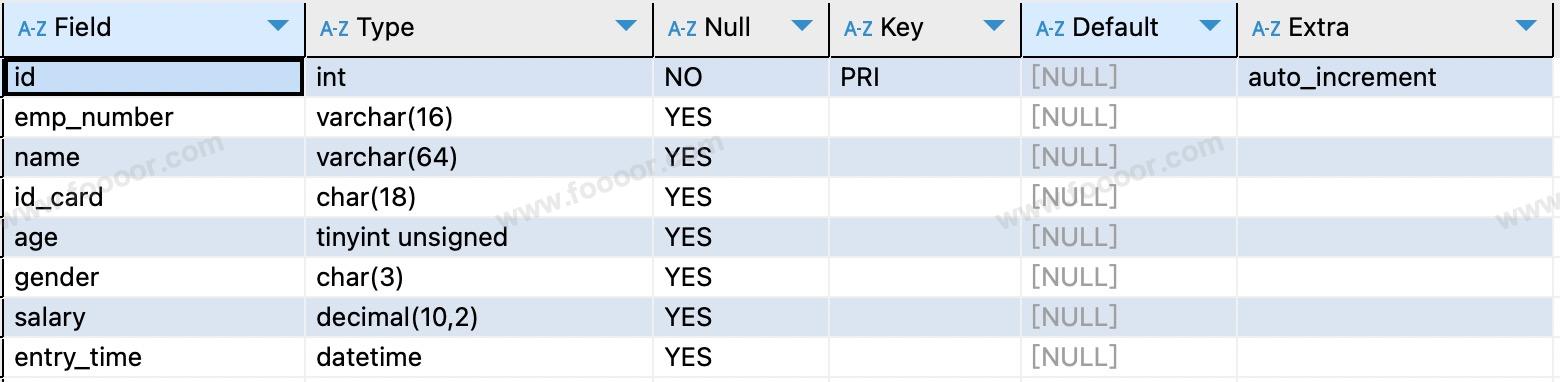
# 2 查看表结构
使用下面的命令可以查看指定表的表结构:
-- 查看指定表的表结构
DESC 表名;
-- 例如,查看 tb_employee 表结
DESC tb_employee;
2
3
4
5
可以看到表中的字段以及字段的相关属性,执行结果如下:
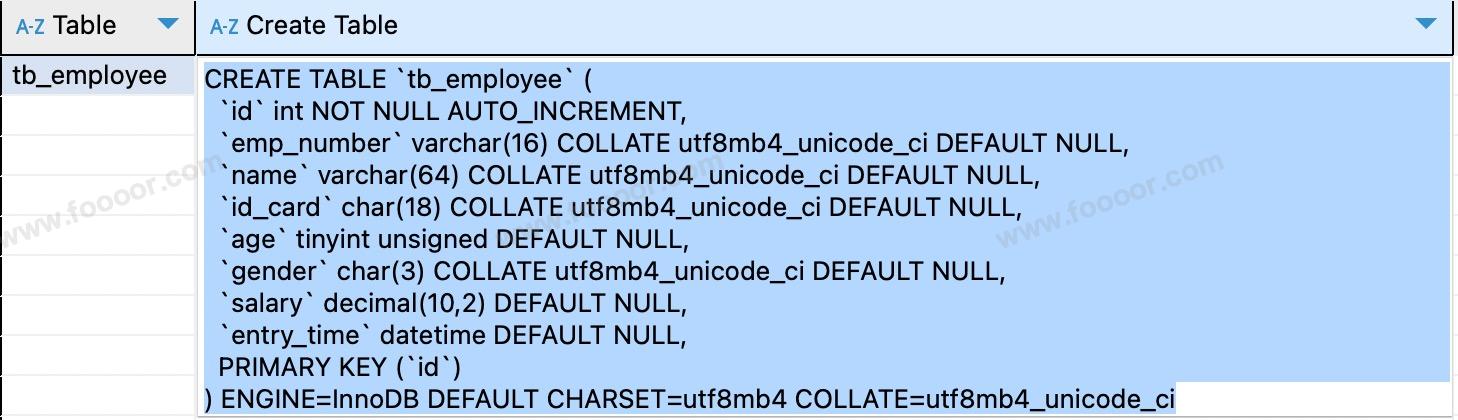
# 3 查看建表语句
上面查看表结构无法查看到字段注释等信息,使用下面的命令可以查看建表语句的信息:
-- 查看指定表的建表语句
SHOW CREATE TABLE 表名;
-- 例如:查看tb_employee表的建表语句
SHOW CREATE TABLE tb_employee;
2
3
4
5
执行结果如下,可以查看到字段注释、字符编码等信息:
# 5.5 删除表
删除指定的表,语法:
-- 删除表
DROP TABLE 表名;
-- 如果存在就删除,不存在不会报错
DROP TABLE IF EXISTS 表名;
2
3
4
5
举个栗子:
-- 例如,删除员工表
DROP TABLE tb_employee;
2