# MySQL教程 - 7 查询
下面开始重头戏,查询!在 SQL 分类中属于 DQL(Data Query Language,数据查询语言)。
查询操作是 SQL 中的重中之重, 在 SQL 操作中,80% 的操作都是在查询表中数据,我们会根据查询条件进行查询,并对数据进行排序等操作。
话不多说,开始。
首先看一下查询的语法:
SELECT 字段列表
FROM 表名列表
WHERE 条件列表
GROUP BY 分组字段列表
HAVING 分组后条件列表
ORDER BY 排序字段列表
LIMIT 限制查询数量
2
3
4
5
6
7
上面看着有点复杂,没关系,慢慢一个一个讲解。
首先准备一下数据,这里执行如下 SQL,向 tb_employee 表插入一些数据,你可以拷贝执行:
-- 先清空一下表
TRUNCATE TABLE tb_employee;
-- 插入数据
INSERT INTO tb_employee (emp_number, name, id_card, age, gender, salary, entry_time) VALUES
('1', '罗辑', '110101198001010011', 42, '男', 12000.50, '2022-03-15 10:30:00'),
('2', '叶文洁', '110101195502020022', 68, '女', 15000.00, '2022-05-20 14:45:00'),
('3', '程心', '110101199003030033', 25, '女', 28000.75, '2023-01-10 09:00:00'),
('4', '史强', NULL, 48, '男', 8000.00, '2022-08-22 16:10:00'),
('5', '庄颜', NULL, 30, '女', 13000.25, '2023-04-05 18:20:00'),
('6', '云天明', '110101198707070066', 35, '男', 18000.00, '2024-06-14 11:45:00'),
('7', '维德', '110101198303030077', 40, '男', 16000.80, '2023-03-02 08:15:00'),
('8', '艾AA', '110101199501050088', 28, '女', 39500.60, '2024-07-07 13:30:00'),
('9', '丁仪', '110101196802080010', 54, '男', 24500.35, '2023-02-11 10:00:00'),
('10', '章北海', '110101197012100011', 50, '男', 19000.90, '2023-01-28 14:00:00'),
('11', '杨冬', '110101199203150012', 31, '女', 12500.00, '2022-11-30 09:15:00'),
('12', '汪淼', '110101198509200013', 38, '男', 14000.50, '2023-05-16 12:00:00'),
('13', '常伟思', '110101197408250014', 54, '男', 11000.00, '2022-10-20 11:00:00'),
('14', '关一帆', '110101199406060015', 28, '男', 10500.70, '2024-06-22 16:45:00'),
('15', '伊文斯', '11010119760309001X', 47, '男', 57500.25, '2023-03-30 13:00:00');
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 7.1 检索数据
# 1 查询所有字段
查询表中所有的数据,如下:
SELECT *
FROM tb_employee;
2
SELECT *表示查询表中所有的字段;FROM tb_employee指定从哪张表中查询;
执行结果:
| id | emp_number | name | id_card | age | gender | salary | entry_time |
|---|---|---|---|---|---|---|---|
| 1 | 1 | 罗辑 | 110101198001010011 | 42 | 男 | 12000.50 | 2022-03-15 10:30:00 |
| 2 | 2 | 叶文洁 | 110101195502020022 | 68 | 女 | 15000.00 | 2022-05-20 14:45:00 |
| 3 | 3 | 程心 | 110101199003030033 | 25 | 女 | 28000.75 | 2023-01-10 09:00:00 |
| ...略 |
# 2 查询指定字段
SELECT * 会返回表中所有列,哪怕有些列你并不需要。这可能导致网络传输的开销增大,尤其是在表字段多或数据量大的情况下。所以一般在实际使用是不推荐使用 SELECT *,
一般都是需要哪些列查询哪些列,所以就需要指定查询的列:
-- 查询表中所有数据,并指定查询的列
SELECT id, emp_number, name, id_card, age, gender
FROM tb_employee;
2
3
- 在 SELECT 后指定查询的列,使用
,分隔。
执行结果:
| id | emp_number | name | id_card | age | gender |
|---|---|---|---|---|---|
| 1 | 1 | 罗辑 | 110101198001010011 | 42 | 男 |
| 2 | 2 | 叶文洁 | 110101195502020022 | 68 | 女 |
| 3 | 3 | 程心 | 110101199003030033 | 25 | 女 |
| ...略 |
# 3 查询别名
查询别名(Alias) 是指查询的时候,可以为字段指定一个别名,提高可读性。在多表连接查询(后面讲)时,可以避免字段名重复。
举个栗子:
-- 为字段设置别名
SELECT id, name as 'employee_name', id_card as '身份证', age, gender
FROM tb_employee;
2
3
- 上面在查询的时候,通过
as关键字,可以为字段设置别名; - 其实
as关键字可以省略的,例如写为SELECT name 'employee_name', id_card '身份证'即可。
执行结果如下,列的名称变了:
| id | employee_name | 身份证 | age | gender |
|---|---|---|---|---|
| 1 | 罗辑 | 110101198001010011 | 42 | 男 |
| 2 | 叶文洁 | 110101195502020022 | 68 | 女 |
| 3 | 程心 | 110101199003030033 | 25 | 女 |
| ...略 |
# 4 去除重复的查询记录
有时候查询出的结果会存在重复,例如查询所有数据的年龄:
SELECT age FROM tb_employee;
结果肯定是存在重复的,那么可以使会用 DISTINCT 关键字去重:
SELECT DISTINCT age
FROM tb_employee;
2
- 通过添加
DISTINCT关键字,结果会去掉重复数据。
# 7.2 查询条件
上面在查询的时候,没有指定查询条件,那么会查询所有的数据,一般在查询的时候,都会通过 WHERE 子句执行查询条件。
SELECT 字段列表
FROM 表名列表
WHERE 条件列表
2
3
举个栗子:
-- 查询 name 为 '罗辑' 的员工信息
SELECT *
FROM tb_employee
WHERE name = '罗辑';
2
3
4
- 通过
WHERE指定查询条件,只查询需要的数据。 - 因为 name 字段是字符串,那么需要使用
''将值括起来,数字类型的不用;
执行结果:
| id | emp_number | name | id_card | age | gender | salary | entry_time |
|---|---|---|---|---|---|---|---|
| 1 | 1 | 罗辑 | 110101198001010011 | 42 | 男 | 12000.50 | 2022-03-15 10:30:00 |
# 1 比较运算符
上面演示的时候,使用了 name = '罗辑' ,使用的是 等于(=) 比较运算符,还有以下运算符可以使用:
| 运算符 | 描述 |
|---|---|
| = | 等于 |
| <> 或 != | 不等于 |
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
举个栗子:
-- 查询年龄大于等于35的员工
SELECT * FROM tb_employee WHERE age >= 35;
-- 查询年龄不等于35的员工
SELECT * FROM tb_employee WHERE age != 35;
2
3
4
5
# 2 逻辑运算符
上面查询的时候,只设置了一个查询条件,查询条件是可以设置多个的,可以通过逻辑运算符连接多个查询条件。
逻辑运算符有如下几个:
| 运算符 | 描述 |
|---|---|
| AND | 同时满足多个条件 |
| OR | 满足任意一个条件 |
| NOT | 对条件取反 |
举个栗子:
-- 查询年龄大于30,并且小于40的员工
SELECT * FROM tb_employee WHERE age > 35 and age < 40;
-- 查询年龄大于35,并且是女性的员工
SELECT * FROM tb_employee WHERE age > 35 AND gender = '女';
-- 查询年龄大于40,或者年龄小于30的员工
SELECT * FROM tb_employee WHERE age > 40 OR age < 30;
-- 查询年龄等于30或40或50的员工,可以多个拼接
SELECT * FROM tb_employee WHERE age = 30 OR age = 40 OR age = 50;
-- 查询年龄不大于35岁的员工,也就是小于等于35,一般不这样用
SELECT * FROM tb_employee WHERE not age > 35;
-- 等价于
SELECT * FROM tb_employee WHERE age <= 35;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
逻辑运算符是有优先级的,NOT > AND > OR。
举个栗子:
-- 查询年龄大于40或者年龄小于30的女性员工
SELECT * FROM tb_employee WHERE (age > 40 OR age < 30) and gender = '女';
2
- 年龄大于40或者年龄小于30是一个条件,因为
OR的优先级小于AND,所以使用括号括起来,否则会查询年龄大于40的员工或者年龄小于30的女性员工。
# 3 范围查询
用于检查某个值是否在指定范围内,包含边界 ,可以使用 BETWEEN ... AND ...。
举个栗子:
-- 查询年龄在30和40之间的员工,包括30和40
SELECT * FROM tb_employee WHERE age BETWEEN 30 AND 40;
-- 效果等价于
SELECT * FROM tb_employee WHERE age >= 30 AND age <= 40;
2
3
4
5
- 注意
AND前面是小值,AND后面是大值,否则查询不到结果。
# 4 集合查询
查询字段是属于指定集合中的记录,如果 OR 的个数比较多,可以使用集合查询。
举个栗子:
-- 查询年龄是30,40,50或60的员工
SELECT * FROM tb_employee WHERE age = 30 OR age = 40 OR age = 50 OR age = 60;
-- OR的条件太多,可以使用in()查询
SELECT * FROM tb_employee WHERE age IN (30, 40, 50, 60);
2
3
4
5
还可以搭配 NOT 查询,查询不在指定集合中的记录:
-- 查询年龄不等于30,40,50,60的员工
SELECT * FROM tb_employee WHERE age NOT IN (30, 40, 50, 60);
2
# 5 模糊查询
模糊查询是用于匹配部分字符串的查询方式。
模糊查询使用 LIKE 关键字,通常结合通配符使用:
%:匹配任意数量的字符(包括 0 个字符)。_:匹配单个任意字符。
举个栗子:
-- 查询身份证号是 110101198 开头的员工,右模糊查询
SELECT * FROM tb_employee WHERE id_card LIKE '110101198%';
2
'110101198%'表示110101198开头,后面跟0个或任意个字符。
-- 查询身份证号码中以 110 开头,2结尾的员工
SELECT * FROM tb_employee WHERE id_card LIKE '110%2';
-- 查询身份证号码最后一位是X的员工,左模糊查询
SELECT * FROM tb_employee WHERE id_card LIKE '%X';
-- 查询身份证号码中中包含1983的员工,前后都使用%
SELECT * FROM tb_employee WHERE id_card LIKE '%1983%';
2
3
4
5
6
7
8
需要注意,一般不太推荐使用左模糊查询('%xx' ),因为会扫描表中所有的记录进行匹配,在数据量大的时候,性能不好。
如果只想跟一个字符,可以使用 _ 通配符,举个栗子:
查询名字以 程 开头,并且名字是两个字的员工。
-- 以姓程的,名字是两个字的员工
SELECT * FROM tb_employee WHERE name LIKE '程_';
-- 查询名字第二个字是'强'的员工
SELECT * FROM tb_employee WHERE name LIKE '_强%';
-- 查询名字是两个字的员工,使用两个_
SELECT * FROM tb_employee WHERE name LIKE '__';
2
3
4
5
6
7
8
# 6 空值检查
IS NULL 用于判断列的值是否为 NULL。
举个栗子:
-- 查询身份证号码为空的员工
SELECT * FROM tb_employee WHERE id_card IS NULL;
-- 查询身份证号码不为空的员工,使用NOT取反
SELECT * FROM tb_employee WHERE id_card IS NOT NULL;
2
3
4
5
# 7.3 查询结果排序
对查询结果排序在实际的开发中是必不可少的,例如商品按照价格排序、订单按照创建时间倒序排序等。
对查询结果排序,使用 ORDER BY 关键字,语法如下:
SELECT 字段列表
FROM 表名
ORDER BY 字段1 排序方式, 字段2 排序方式, ...
2
3
排序方式有两种方式:升序(ASC) 和 降序(DESC),排序方式可以省略,省略默认为升序。
# 1 单个字段排序
举个栗子:
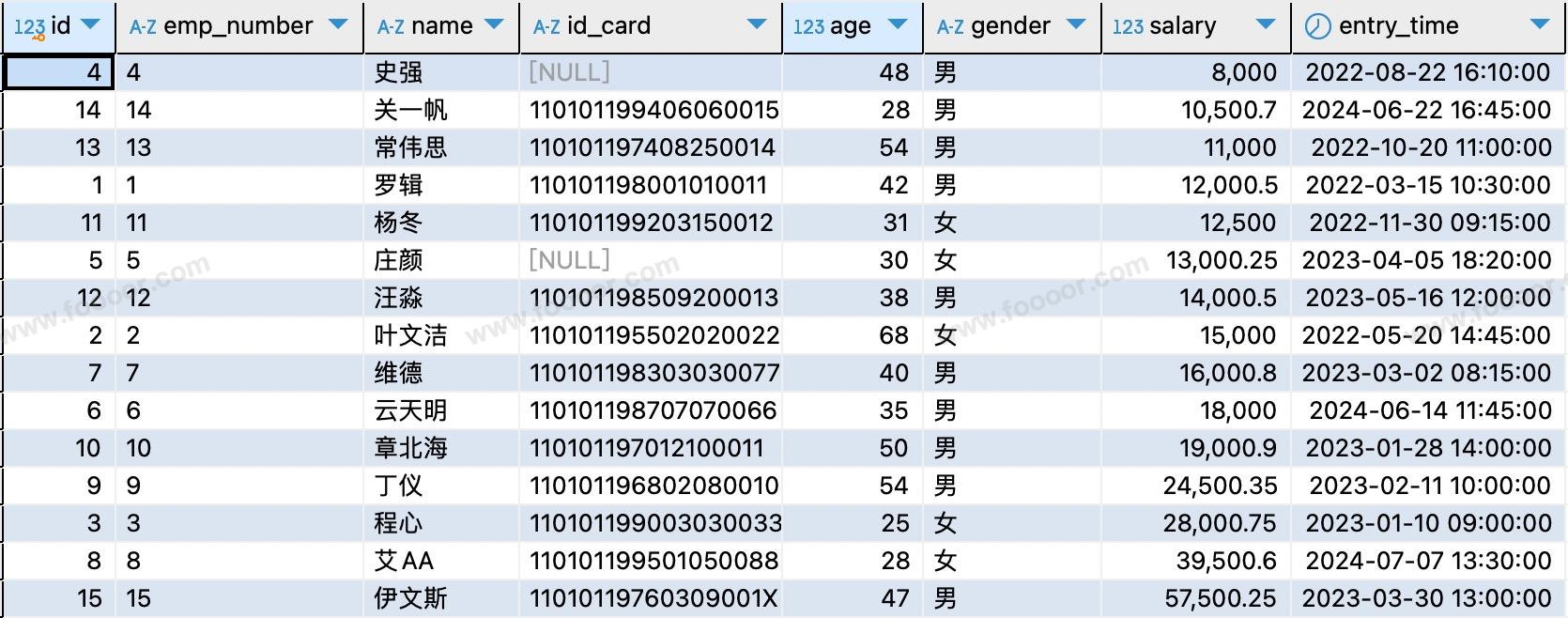
-- 查询所有员工,按照工资升序排列
SELECT * FROM tb_employee ORDER BY salary ASC;
-- ASC可以省略,默认升序
SELECT * FROM tb_employee ORDER BY salary;
2
3
4
5
执行结果:
降序排列:
-- 查询所有员工,按照工资降序排列
SELECT * FROM tb_employee ORDER BY salary DESC;
2
# 2 多个字段排序
排序可以按照多列进行排序,在进行多列排序的时候,会将结果先按照第一列排序,第一列相同的情况下,再按照第二列排序。
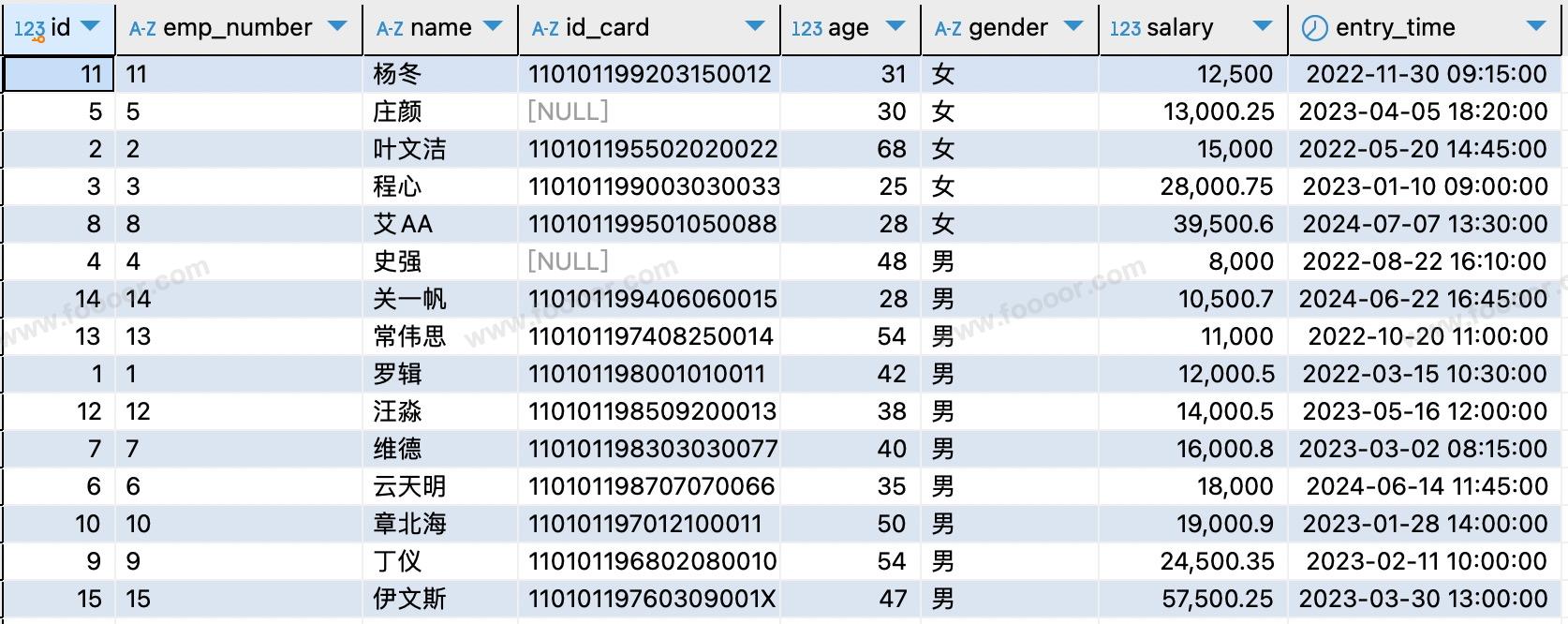
例如:先按照性别升序排列,然后按照工资升序排列:
-- 按照性别和工资排序
SELECT * FROM tb_employee ORDER BY gender, salary;
-- 或者使用
SELECT * FROM tb_employee ORDER BY gender, salary ASC;
-- 或者使用
SELECT * FROM tb_employee ORDER BY gender ASC, salary ASC;
2
3
4
5
6
7
8
- 会先按照性别升序排序,性别相同的情况下,按照工资升序排序。
执行结果:
再举个栗子:
按照年龄升序排序,如果年龄相同,按照入职时间降序排列:
SELECT * FROM tb_employee ORDER BY age ASC, entry_time DESC;