Appearance
MySQL教程 - 7 查询
继续讲解查询...
7.4 聚合函数
在 SQL 中,聚合函数用来对表中的列数据进行计算,例如求某一列的最大值、最小值、平均值;求某一列的总和等。最常用的是求查询出的结果总共有多少条记录。下面分别介绍一下。
1 查询数量COUNT
COUNT() 函数就是用来求查询满足条件的记录数。
举个栗子:
sql
-- 查询tb_employee表中的总记录数
SELECT COUNT(*) FROM tb_employee;
-- 或者根据 主键 查询也可以
SELECT COUNT(id) FROM tb_employee;
-- 查询男性员工的总数
SELECT COUNT(id) FROM tb_employee WHERE gender = '男';- 因为主键不能为空,所以使用主键可以查询,需要注意:不要以存在空(NULL)的列进行查询,因为 NULL 不参与所有聚合函数的运算,下同,所以
COUNT(column)只计算指定列中非 NULL 的行数。
执行结果:

在 id 是主键的情况下,COUNT(*) 和 COUNT(id) 性能区别不大,因为在大多数数据库中,COUNT(*) 是经过优化的统计方式,例如缓存了表的总行数。
2 查询总数SUM
SUM() 函数可以求满足条件的某一列值的数据之和,是对某一列的值进行求和(忽略 NULL 值)。
举个栗子:
sql
-- 查询所有人的年龄之和
SELECT SUM(age) FROM tb_employee;执行结果:

当然,也可以根据查询条件查询:
sql
-- 查询男性员工的年龄之和
SELECT SUM(age) FROM tb_employee WHERE gender = '男';
-- 查询女性员工的工资之和
SELECT SUM(salary) FROM tb_employee WHERE gender = '女';3 查询最大最小值
MIN()函数:求某一列的最小值;MAX()函数:求某一列的最大值;
适用于数值、日期、文本数据(按字段顺序排序)。
举个栗子:
sql
-- 查询最大年龄的员工
SELECT MAX(age) FROM tb_employee;
-- 查询最高工资的女性员工
SELECT MAX(salary) FROM tb_employee WHERE gender = '女';4 查询平均值
AVG() 函数可以求某一列的平均值。只计算非 NULL 值。
举个栗子:
sql
-- 计算所有人的平均工资
SELECT AVG(salary) FROM tb_employee;
-- 计算男性员工的平均工资
SELECT AVG(salary) FROM tb_employee WHERE gender = '男';需要注意:NULL值不参与所有聚合函数的运算。
7.5 分组查询
分组查询就是可以对表中的一列或多列数据进行分组,并对分组的数据进行聚合(如求和、计数等)操作。
语法:
sql
SELECT 字段列表 FROM 表名 [WHERE 条件列表] GROUP BY 分组字段 [HAVING 分组过滤条件];说了也不太好明白,举栗子吧。
1 分组查询
如果想查询员工表中,男员工和女员工的数量,该如何查询?
要查询男员工和女员工的数量,首先需要根据性别进行分组,然后统计着两个分组中的员工的数量。
sql
-- 根据 gender 分组
SELECT COUNT(gender) FROM tb_employee GROUP BY gender;执行结果:

上面只是按照性别进行分组,并查询到了两个分组,数量分别是 10 和 5,但是并不知道哪个性别对应哪个数量,我们可以将分组的列作为字段列进行查询:
sql
-- 根据 gender 分组
SELECT gender, COUNT(gender) FROM tb_employee GROUP BY gender;执行结果:

需要注意,使用分组查询的时候,字段列表中( SELECT后面的 )只能是进行分组的字段和聚合函数,你可以想象,如果此时把 name 也查询出来:
sql
-- name 没有意义,可能会报错
SELECT name, gender, COUNT(gender) FROM tb_employee GROUP BY gender;显然这个 name 是没有意义的,我们是按照 gender 进行分组了,COUNT(gender) 是统计每个性别的数量,这个时候 name 肯定是不能显示某个员工的 name 的。
再举几个栗子:
sql
-- 统计男性和女性的平均年龄
SELECT gender, AVG(age) FROM tb_employee GROUP BY gender;
-- 统计年龄大于35岁的,男性和女性的平均工资
SELECT gender, AVG(salary) FROM tb_employee WHERE age > 35 GROUP BY gender;2 分组过滤条件
分组过滤条件可以对分组查询出的结果进行过滤。使用 HAVING 关键字。
举个栗子:
如果要查询员工有哪些年龄,每个年龄有多少人,可以使用年龄进行分组,查询每个年龄的人数:
sql
-- 根据年龄分组,并排序
SELECT age, COUNT(age)
FROM tb_employee
GROUP BY age
ORDER BY age ASC;执行结果如下:

如果我想查看哪些年龄是有同龄人的,也就是哪个年龄的人数 > 1,这里其实是对结果进行过滤,查看 COUNT(age) > 1 的数据,需要用 HAVING 来过滤:
sql
SELECT age, COUNT(age)
FROM tb_employee
GROUP BY age
HAVING COUNT(age) > 1
ORDER BY age ASC;执行结果:

可以看出,WHERE 是在分组之前进行过滤,不满足 WHERE 条件,不会参与分组;而 HAVING 是在分组之后对结果进行过滤。另外 WHERE 后面是无法使用聚合函数进行过滤的。
3 多个分组
多个分组条件通常用于对数据进行更细粒度的分类。
上面对性别进行分组,结果就是性别的个数,也就是 2;对年龄进行分组,结果就是年龄的个数,如果同时使用性别和年龄进行分组,结果的个数 = 性别(个数) * 年龄(个数) 。
查询出的结果是每个性别、每个年龄的人的个数:
sql
SELECT gender, age, COUNT(age)
FROM tb_employee
GROUP BY gender, age
ORDER BY gender, age ASC;执行结果:
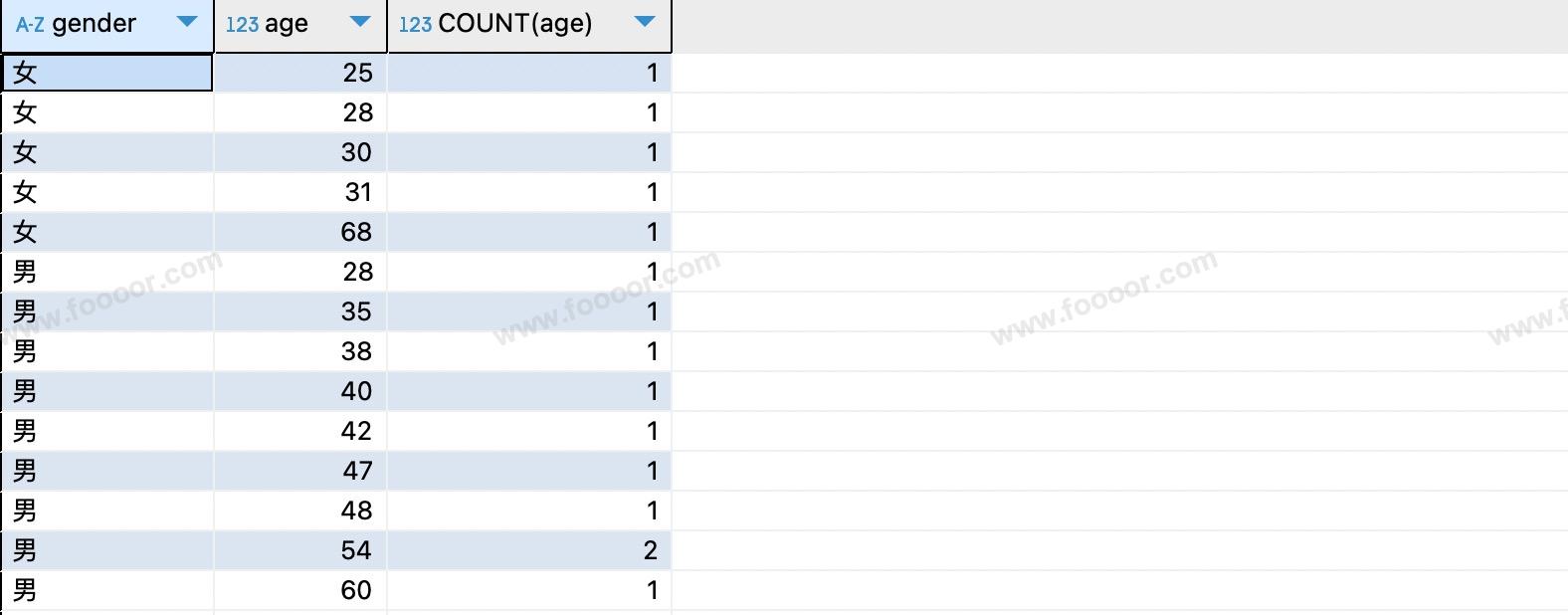
使用两个字段分组,查询到的数据是在这两个维度上依次匹配这两种关系,是更细粒度的查询。
再举个栗子说明一下,有一张销售统计表 tb_prod_sales,包含了 id、商品名称、日期,商品数量 字段,用来统计每天每个商品卖出的个数。
| id | prod_name | sales_date | prod_count |
|---|---|---|---|
如果按照 日期(每天)来分组,那就是每天卖出的商品总数(SUM(商品数量)):
sql
-- 查询每天销售商品的总数
SELECT sales_date, SUM(prod_count)
FROM tb_prod_sales
GROUP BY sales_date;如果按照 商品名称 来分组,就是统计每个商品总共卖出的总数(SUM(商品数量)):
sql
-- 查询每件商品销售的总数
SELECT prod_name, SUM(prod_count)
FROM tb_prod_sales
GROUP BY prod_name;如果同时按照 商品 和 日期 来分组,那就是统计每个商品每天卖出的数量:
sql
-- 查询每件商品、每天销售的数量
SELECT prod_name, sales_date, SUM(prod_count)
FROM tb_prod_sales
GROUP BY prod_name, sales_date;7.6 分页查询
LIMIT 关键字是 MySQL 中用于控制查询返回结果数量的子句,我们一般用它来进行分页查询,因为它可以控制返回结果的起始位置和返回结果的数量。LIMIT 属于 MySQL 数据库的方言,因为不同的 DBMS 控制返回结果数量的语句是不一样的。
MySQL 中语法如下:
sql
SELECT 字段列表 FROM 表名 LIMIT offset, row_count;offset:表示返回的结果的起始索引,从 0 开始。该参数可以省略,就表示从 0 开始,也就是从第一条数据开始;row_count:表示返回几条记录。
一般在页面上会有类似下图这样的分页信息:

以查询员工表信息为例,查询第一页信息,SQL 如下:
sql
-- 查询所有员工,每页10条,查询第一页
SELECT * FROM tb_employee LIMIT 0, 10;
-- 也可以省略offset
SELECT * FROM tb_employee LIMIT 10;上面是查询第一页的信息,如果要查询第二页,那么查询语句如下:
sql
-- 查询所有员工,每页10条,查询第二页
SELECT * FROM tb_employee LIMIT 10, 10;- 从索引为 10 的位置开始查询,也就是从第 11 条开始查询,查询 10 条,也就是说
起始索引 = (查询页码 - 1) * 每页数量。
添加排序:分页查询第二页数据,每页10条,按照入职时间倒序排序:
sql
-- 分页查询,按照创建时间倒序排序
SELECT * FROM tb_employee ORDER BY entry_time DESC LIMIT 10, 10;添加查询条件:查询男员工,分页查询第二页数据,每页显示3条,按照入职时间倒序排序:
sql
SELECT * FROM tb_employee WHERE gender = '男' ORDER BY entry_time DESC LIMIT 6, 3;查询最后一个入职的员工,根据入职时间倒序排列,取第一条数即可:
sql
-- 查询表中最新的一条数据
SELECT * FROM tb_employee ORDER BY entry_time DESC LIMIT 1;