Appearance
Python教程 - 5 容器(2)
继续讲容器...
5.4 容器的切片
什么是切片?
切片就是截取容器中的一部分元素形成一个新的列表。
切片支持从指定位置开始,依次取出元素,到指定位置结束,得到一个新的序列。
所以容器必须是有序的序列,列表、元组、字符串都支持切片操作。
语法:
python
序列[起始下标:结束小标:步长]起始下标表示从截取开始的位置,可以不写,不写表示从头开始;
结束下标表示截取结束的位置,也可以不写,不写表示截取到结尾。
步长表示取出元素的间隔
步长为1,表示一个一个取出元素,步长可以不写,不写默认为1;
步长为2,表示间隔一个元素取一个元素,以此类推;
步长可以为负数,表示倒序来取,此时起始下标和结束下标也需要反过来写。
注意:切片不会影响原来的系列,而是会得到一个新的序列。
举个栗子1:
python
num_list = [1, 2, 3, 4, 5]
new_list1 = num_list[1:4:1]
new_list2 = num_list[1:4]
print(new_list1)
print(new_list2)从下标1开始,下标4结束(不包含该位置),步长为1
执行结果:
[2, 3, 4]
[2, 3, 4]举个栗子2:
python
num_list = [1, 2, 3, 4, 5]
new_list = num_list[:4:2]
print(new_list)从头开始,下标4结束,步长为2
执行结果:
[1, 3]举个栗子3:
python
num_list = [1, 2, 3, 4, 5]
new_list = num_list[::2]
print(new_list)从头开始,到末尾结束,步长为2
执行结果:
[1, 3, 5]举个栗子4:
python
num_list = [1, 2, 3, 4, 5]
new_list = num_list[:]
print(new_list)从头开始,到末尾结束,步长为1
执行结果:
[1, 2, 3, 4, 5]举个栗子5:
python
num_list = [1, 2, 3, 4, 5]
new_list = num_list[3:1:-1]
print(new_list)步长为-1,表示倒序来取,此时开始位置从下标为3的位置开始,结束位置下标为1(不包含)。
执行结果:
[4, 3]举个栗子6:
python
num_list = (1, 2, 3, 4, 5)
new_list = num_list[:1:-2]
print(new_list)序列是一个元组,步长为-2,此时开始位置表示序列的结尾开始,结束位置下标为1(不包括)。
执行结果:
(5, 3)举个栗子7:
python
str = "Hello"
new_str = str[::-1]
print(new_str)序列为字符串,步长为-1,此时开始位置表示序列的结尾开始,到序列的开始位置结束。
这种方式可以用来让字符串倒序。
执行结果:
olleH5.5 容器的内存结构
下面以列表为例,讲解容器的内存结构,这样更利于我们理解某些操作的原理。
先看代码:
python
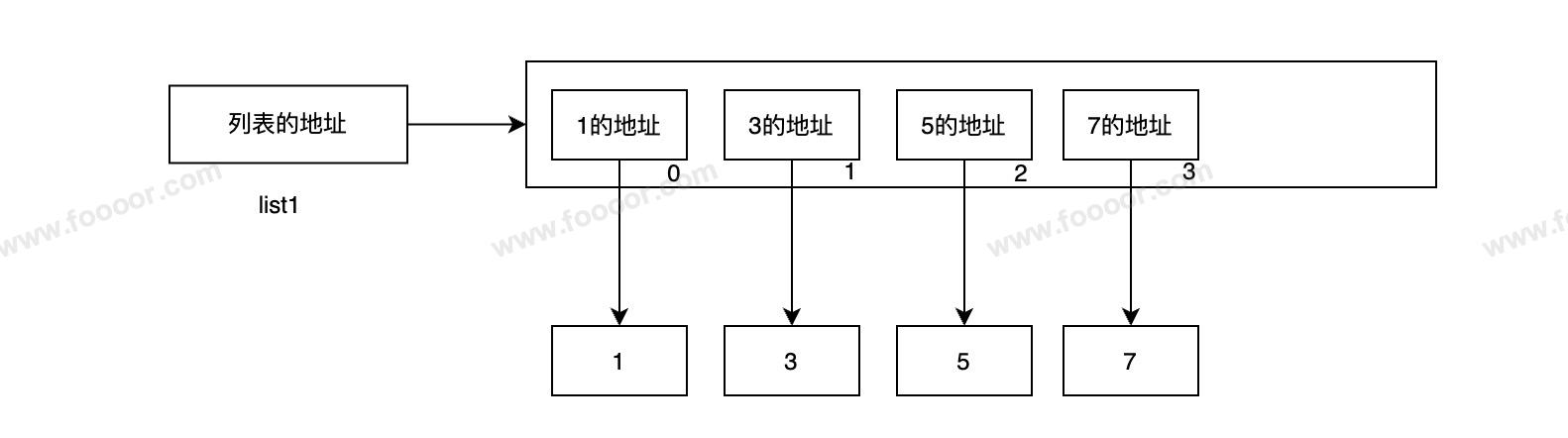
list1 = [1, 3, 5, 7]在内存中的存储结构如下:
列表中并不是直接存储了元素,而是存储了元素的地址。
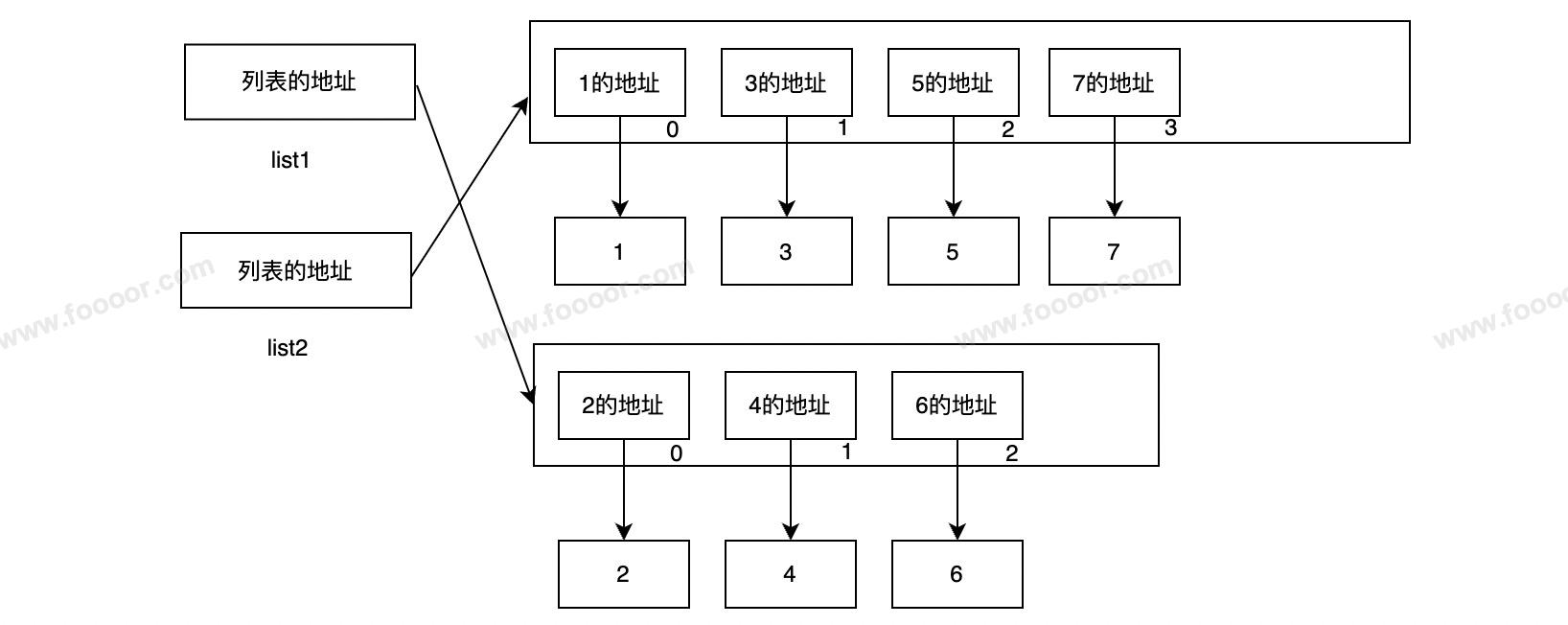
看下面的代码,list2的结果是?
python
list1 = [1, 3, 5, 7]
list2 = list1
list1 = [2, 4, 6]
print(list2) # [1, 3, 5, 7]执行完的内存结构图:
就是首先list2 = list1将list2指向了list1指向的列表,然后list1又指向了一个新的列表。
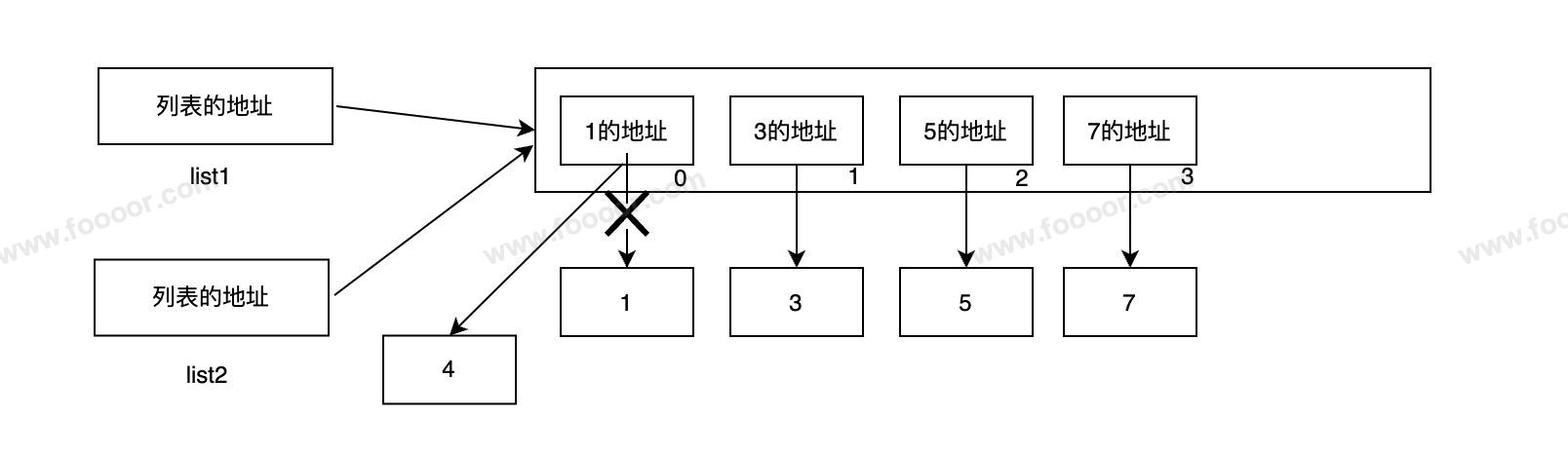
看下面的代码,list2的结果是?
python
list1 = [1, 3, 5, 7]
list2 = list1
list1[0] = 4
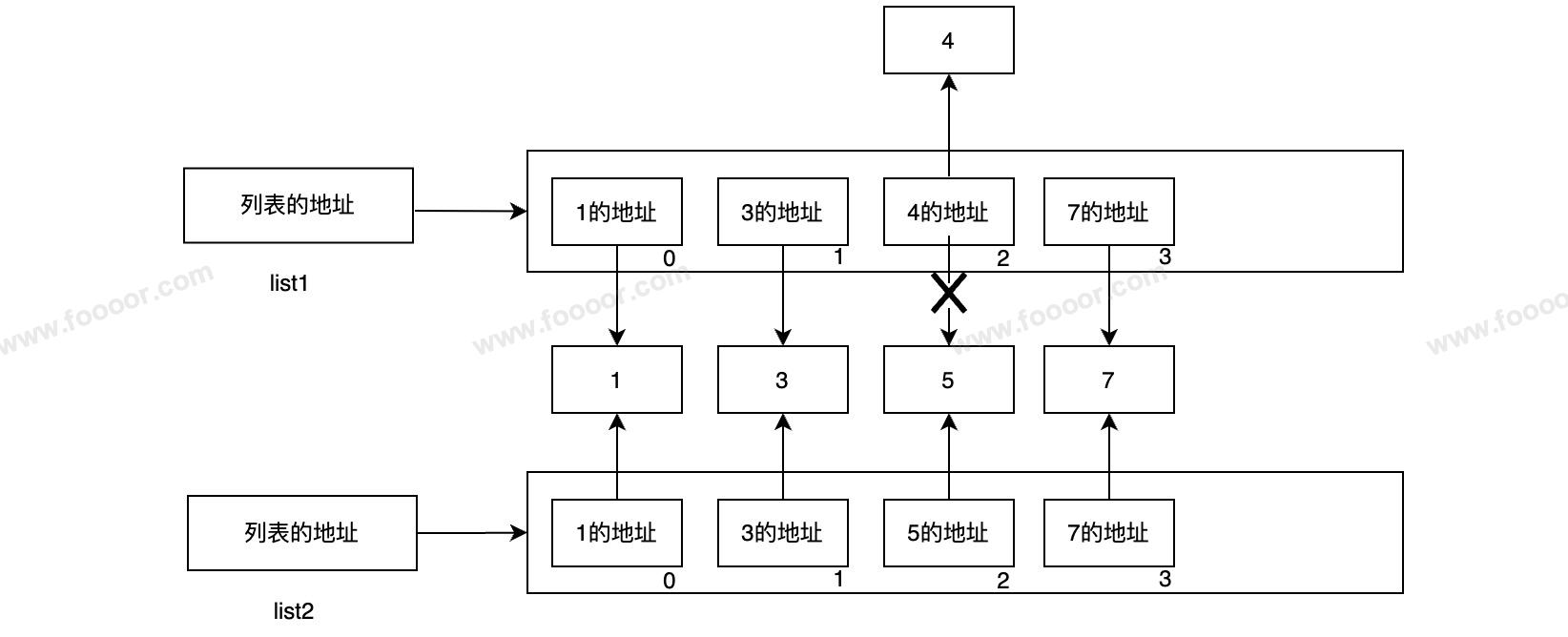
print(list2) # [4, 3, 5, 7]执行完的内存结构图:
首先list2 = list1将list2指向了list指向的集合,然后修改了集合中第一个元素的指向,创建了4,并将集合中的第一个元素指向了4。
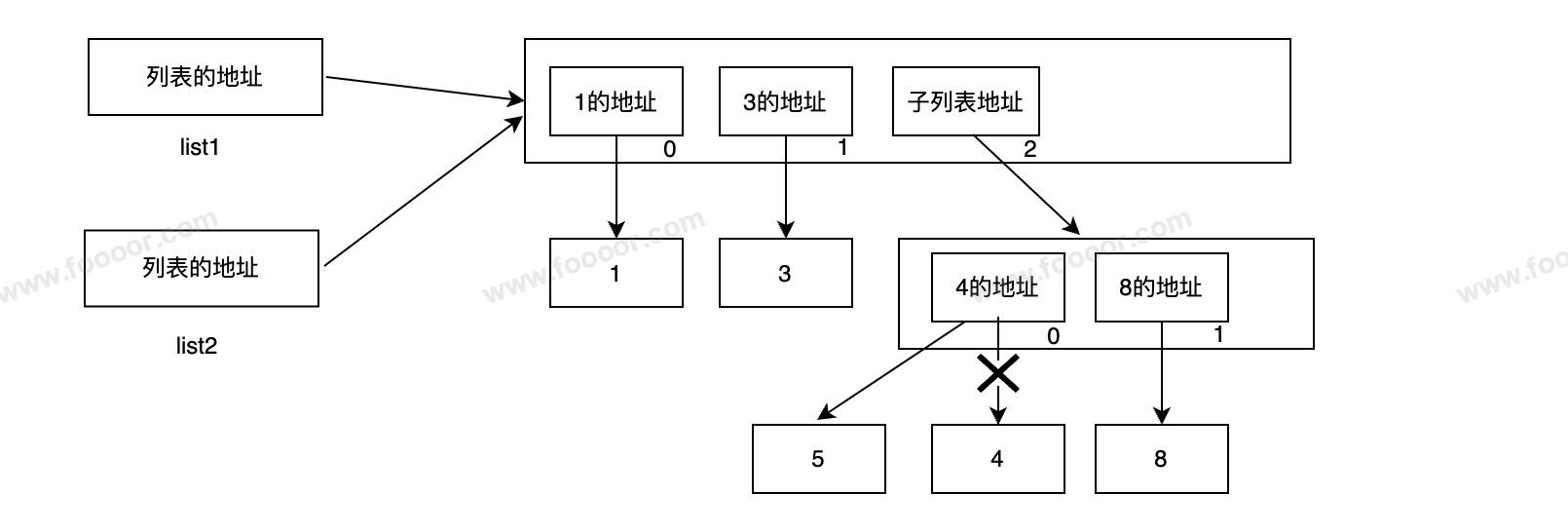
看下面的代码,list2的结果是?
python
list1 = [1, 3, [4, 8]]
list2 = list1
list1[2][0] = 5
print(list2) # [1, 3, [5, 8]]执行完的内存结构图:
看下面的代码,list2的结果是?
python
list1 = [1, 3, 5, 7]
list2 = list1[:]
list1[2] = 4
print(list1) # [1, 3, 4, 7]
print(list2) # [1, 3, 5, 7]执行完的内存结构图:
切片是重新创建了一个列表,但是列表中的元素是指向了原来数组元组指向的地址。
如果重新赋值,那么会重新指向新的地址。
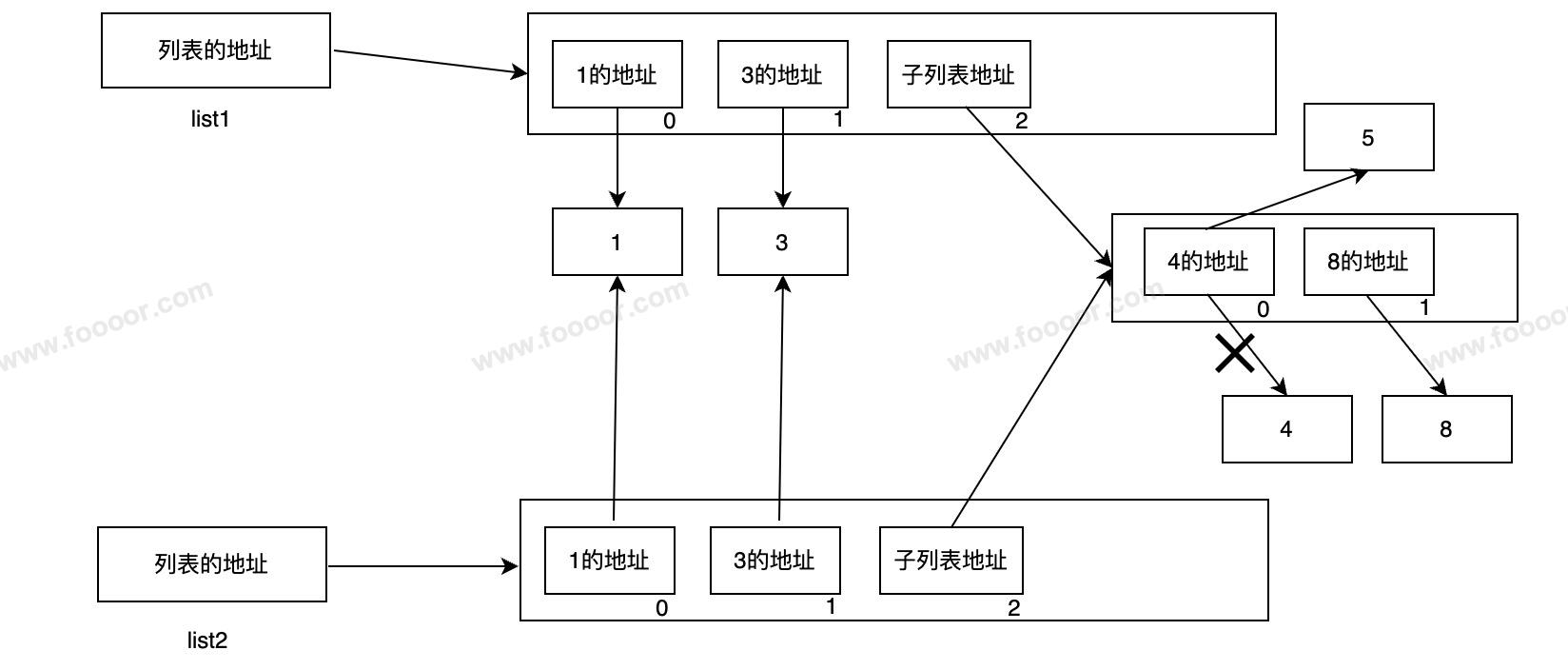
看下面的代码,list2的结果是?
python
list1 = [1, 3, [4, 8]]
list2 = list1[:]
list1[2][0] = 5
print(list1) # [1, 3, [5, 8]]
print(list2) # [1, 3, [5, 8]]执行完的内存结构图:
切片是重新创建了一个列表,但是只会复制原来列表的第一层数据,更深层次的子列表,是不会复制的,两个列表指向的是相同的地址。
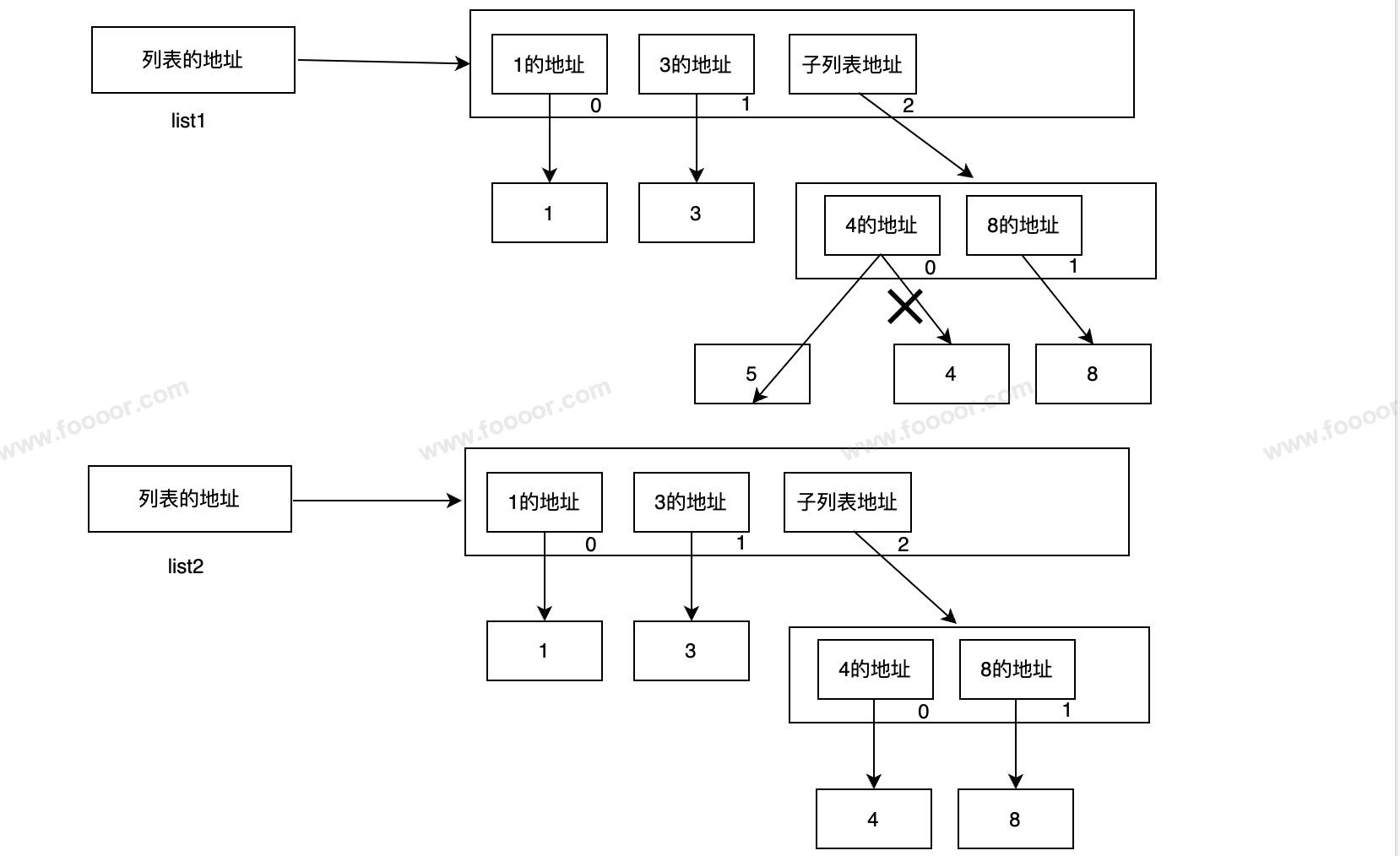
1 深拷贝
上面这种通过切片的方式复制容器形成一个新容器的方式为浅拷贝的方式,只能赋值容器的第一层数据;
还有一种是深拷贝的方式,就是拷贝一个容器形成另外一个容器,这两个容器就是两个完全独立的容器了。
下面介绍一下深拷贝的方式:
python
import copy # 引入copy依赖
list1 = [1, 3, [4, 8]]
list2 = copy.deepcopy(list1)
list1[2][0] = 5
print(list1) # [1, 3, [5, 8]]
print(list2) # [1, 3, [4, 8]]首先引入copy包,然后使用deepcopy方法进行深拷贝。
执行完成的内存结构图如下:
这种方式就比较简单了,复制完成就完全是两个独立的容器了,两者之间不会出现任何关系。
这种深拷贝的方式在实际的开发中用的不多。
5.6 集合(set)
已经有列表和元组了,感觉已经很强大了,为什么还需要集合呢?
列表和元组都支持重复的元素,如果需要对内容进行去重,就显得有些不方便了。
集合更重要的是用来做一些运算,例如求两个容器的交集、并集、差集等。
集合最主要的特点:
- 不支持重复的元素
- 内容是无序的,不能下标来访问元素
- 集合是可以被修改的
- 可以存储不同的数据类型
1 集合的定义
使用 花括号{} 来定义集合。
python
# 定义一个集合,并赋值给一个变量
变量名称 = {元素1, 元素2, 元素3, ...}
# 定义空集合
变量名称 = set()举个栗子:
python
my_set = {"Good" , "good", "study", "day", "day", "up"}
print(my_set)执行结果:
{'Good', 'good', 'day', 'up', 'study'}可以看出虽然在集合中添加了重复的元素,但是最终被去重了,而且可以看出集合是无序的。
2 集合的常用操作
集合长度
使用 len() 函数获取集合的长度。
python
my_set = {1, 2, 3, 4, 5}
print(len(my_set))执行结果:
5添加元素
使用 .add() 方法,可以将指定的元素,添加到集合内。
集合本身被修改,不会产生新集合。
python
my_set = {"I", "love"}
my_set.add("you")
print(my_set)执行结果:
{'I', 'love', 'you'}删除元素
使用 .remove() 方法,可以将指定的元素,从集合中移除。
集合本身被修改,不会产生新集合。
python
my_set = {"I", "love", "you"}
my_set.remove("you")
print(my_set)执行结果:
{'love', 'I'}取出元素
使用 .pop() 方法,可以从集合中随机取出一个元素。
集合本身被修改,不会产生新集合。
python
my_set = {"I", "love", "you"}
word = my_set.pop()
print(word)
print(my_set)执行结果:
I
{'love', 'you'}每次执行的结果可能不一样。
清空集合
使用 .clear() 方法,可以将集合清空。
集合本身被修改,不会产生新集合。
python
my_set = {"I", "love", "you"}
my_set.clear();
print(my_set)执行结果:
set()结果变成了一个空集合。
并集
并集可以使用 | 运算符求出两个集合共有的元素。
python
set1 = {1, 2, 3, 4}
set2 = {1, 3, 5, 7}
set3 = set1.union(set2) # 并集
print(set3)
set4 = set1 | set2 # 并集
print(set4)执行结果:
{1, 2, 3, 4, 5, 7}
{1, 2, 3, 4, 5, 7}交集
交集可以使用 & 运算符或 集合1.intersection(集合2) 方法,获取集合1和集合2的交集,最终会得到一个新集合,集合1和集合2不变。
python
set1 = {1, 2, 3, 4}
set2 = {1, 3, 5, 7}
set3 = set1 & set2 # 交集
print(set3)
set4 = set1.intersection(set2) # 交集
print(set4)执行结果:
{1, 3}
{1, 3}补集
可以使用 ^ 运算符求出两个集合的补集,补集也就是只在一个集合中存在的元素。
python
set1 = {1, 2, 3, 4}
set2 = {1, 3, 5, 7}
set3 = set1 ^ set2
print(set3)执行结果:
{2, 4, 5, 7}差集
使用 集合1.difference(集合2) 方法,可以得到集合1中存在而集合2中不存在的元素。
集合1和集合2不变,最终返回的是一个新的集合。
python
set1 = {1, 2, 3, 4}
set2 = {1, 3, 5, 7}
set3 = set1.difference(set2)
print(set3)执行结果:
{2, 4}差集_更新
使用 集合1.difference_update(集合2) 方法,可以删除集合1内和集合2内相同的元素。
和 集合1.difference(集合2) 方法很相似,但是会更新集合1,集合2不变。
python
set1 = {1, 2, 3, 4}
set2 = {1, 3, 5, 7}
set1.difference_update(set2)
print(set1)执行结果:
{2, 4}判断是否是子集或超集
可以使用 大于号> 或 小于号< 来判断一个集合是否是另一个集合的子集或超集。
python
set1 = {1, 2, 3}
set2 = {1, 3}
print(f"set1是否是set2的超集: {set1 > set2}")
print(f"set2是否是set1的子集: {set2 < set1}")执行结果:
set1是否是set2的超集: True
set2是否是set1的子集: True集合的遍历
因为集合是无序的,不支持下标索引,所以无法使用while循环来遍历。
for循环遍历:
python
my_set = {1, 2, 3, 4, 5}
for num in my_set:
print(num)执行结果:
1
2
3
4
55.7 字典(dict)
什么是字典?
字典和集合有一些相似,但是字段的存储数据是使用键值对,key-value的方式存储数据。
例如有一份数据:
| 姓名 | 成绩 |
|---|---|
| zhangsan | 94 |
| lisi | 96 |
| wangwu | 91 |
使用列表、集合的方式存储上面的数据是很不方便的。
而使用字典存储就很适合,可以将姓名作为key,成绩作为value。
python
{
"zhangsan": 94,
"lisi": 96,
"wangwu": 91
}这样可以很容易通过姓名key得到对应的成绩value。
5.7.1 字典的定义
字典同样是使用 花括号{} 来定义的,但是存储的元素是一个一个的键值对。
python
# 定义字典变量
变量名称 = {key1: value1, key2: value2, key3: value3, ...}
# 定义空字典
变量名称 = {}key 和 value 使用冒号分隔,每一对使用逗号分隔
key 和 value可以是任意类型的数据,不过key不能是字典
key不可以重复,重复会覆盖已存在的数据
举个栗子:
python
stu_dict = {"zhangsan": 94, "lisi": 96, "wangwu": 91}
print(stu_dict)执行结果:
{'zhangsan': 94, 'lisi': 96, 'wangwu': 91}5.7.2 字典的嵌套
刚才说了 key 和 value 可以是任意数据类型,key不能为字典,说明字典是可以嵌套的。
例如我们要记录学生各科的成绩:
| 姓名 | 语文 | 数学 | 英语 |
|---|---|---|---|
| zhangsan | 86 | 91 | 79 |
| lisi | 87 | 88 | 89 |
| wangwu | 92 | 81 | 86 |
那么可以定义一下字典:
python
stu_dict = {
"zhangsan": {"Chinese":86, "Math":91, "English": 79},
"lisi": {"Chinese":87, "Math":88, "English": 89},
"wangwu": {"Chinese":92, "Math":81, "English": 86}
}key是可以使用汉字的,但是不建议。
5.7.3 字典的常用操作
1 获取元素的值
字典是无序的,所以不能通过下标来访问,可以使用 字典[key] 或 字典.get(key) 方法通过key来获取value的值。
python
stu_dict = {
"zhangsan": {"Chinese":86, "Math":91, "English": 79},
"lisi": {"Chinese":87, "Math":88, "English": 89},
"wangwu": {"Chinese":92, "Math":81, "English": 86}
}
print(stu_dict.get("zhangsan"))
print(stu_dict["zhangsan"])
print(stu_dict["zhangsan"]["Chinese"])
print(stu_dict.get("zhangsan").get("Chinese"))执行结果:
{'Chinese': 86, 'Math': 91, 'English': 79}
{'Chinese': 86, 'Math': 91, 'English': 79}
86
86注意:当我们根据key获取值的时候,如果key在字典中不存在是会报错的。
所以我们在获取的时候,要先判断当前的key是否存在:
python
if "zhangsan" in stu_dict: # 先判断有没有“zhangsan“的key
print(stu_dict["zhangsan"])
if "zhaoliu" not in stu_dict:
print("不存在赵六")后面的操作很多都是需要判断key是否存在的, 否则会报错。
2 字典的长度
同样,获取字典内所有元素的数量也是使用 len 函数。
python
stu_dict = {
"zhangsan": 94,
"lisi": 96,
"wangwu": 91
}
print(len(stu_dict))执行结果:
33 新增或更新元素
可以使用 字典[key] = value 的方式新增或更新字典中的元素,字典中没有对应的key,为新增,有则为更新。
python
stu_dict = {
"zhangsan": 94,
"lisi": 96,
"wangwu": 91
}
stu_dict["zhaoliu"] = 83 # 没有对应的key,为新增
stu_dict["zhangsan"] = 88 # 已经存在的key,为更新
print(stu_dict)执行结果:
{'zhangsan': 88, 'lisi': 96, 'wangwu': 91, 'zhaoliu': 83}4 删除元素
可以使用 字典.pop(key) 方法,可以根据key获取指定的value,并将指定key的数据删除。
python
stu_dict = {
"zhangsan": 94,
"lisi": 96,
"wangwu": 91
}
score = stu_dict.pop("lisi")
print(score)
print(stu_dict)执行结果:
96
{'zhangsan': 94, 'wangwu': 91}也可以直接使用 del 函数删除元素:
python
stu_dict = {
"zhangsan": 94,
"lisi": 96,
"wangwu": 91
}
del stu_dict["lisi"]
print(stu_dict)执行结果:
{'zhangsan': 94, 'wangwu': 91}5 清空字典
可以使用 字典.clear() 方法,清空字典。
python
stu_dict = {
"zhangsan": 94,
"lisi": 96,
"wangwu": 91
}
stu_dict.clear()
print(stu_dict)执行结果:
{}6 获取全部的key
可以使用 字典.keys() 方法获取字典中所有的key。
python
stu_dict = {
"zhangsan": 94,
"lisi": 96,
"wangwu": 91
}
keys = stu_dict.keys()
print(keys)
keys_list = list(keys) # 可以使用list()函数,将返回的所以的key转换为列表
print(keys_list)执行结果:
dict_keys(['zhangsan', 'lisi', 'wangwu'])
['zhangsan', 'lisi', 'wangwu']同样也可以通过 字典.values() 来获取字典所有的value。
7 字典的遍历
因为字典是无序的,所以不支持使用 while 循环来遍历。所以只能使用for循环来遍历。
for循环遍历:
python
stu_dict = {
"zhangsan": 94,
"lisi": 96,
"wangwu": 91
}
for item in stu_dict.items(): # 遍历所有元素
print(f"key={item[0]}, value={item[1]}")执行结果:
key=zhangsan, value=94
key=lisi, value=96
key=wangwu, value=91我们也可以先需要使用 字典.keys() 方法获取字典中所有的key,然后再使用for循环遍历:
python
stu_dict = {
"zhangsan": 94,
"lisi": 96,
"wangwu": 91
}
keys = stu_dict.keys() # 首先获取到所有的key
for key in keys: # 遍历所有的key
print(f"key={key}, value:{stu_dict[key]}") # 通过key获取valuezhi首先获取到所有的key,然后使用for循环遍历所有的可以,在遍历的时候,通过key获取到所有的value值。
执行结果:
key=zhangsan, value:94
key=lisi, value:96
key=wangwu, value:915.7.4 总结:字典的特点
- 可以容纳多个不同类型的数据
- 每一份数据是key-value的方式存储,可以通过key获取到value
- 不支持下标索引
- 支持修改
- 可以使用for循环遍历,不支持while循环遍历
5.8 各个容器对比
上面介绍了列表、元组、字符串、集合、字典,下面用表格来比较一下各个的特点,以及使用场景。
| 功能 | 列表 | 元组 | 字符串 | 集合 | 字典 |
|---|---|---|---|---|---|
| 元素数量 | 支持多个 | 支持多个 | 支持多个 | 支持多个 | 支持多个 |
| 元素类型 | 任意 | 任意 | 仅字符 | 任意 | key:除字典外任意类型 value:任意 |
| 下标索引 | 支持 | 支持 | 支持 | 不支持 | 不支持 |
| 重复元素 | 支持 | 支持 | 支持 | 不支持 | 不支持 |
| 可修改 | 支持 | 不支持 | 不支持 | 支持 | 支持 |
| 是否有序 | 是 | 否 | 是 | 否 | 否 |
| 使用场景 | 可修改、可重复的 批量数据 | 不可修改、可重复的 批量数据 | 一串字符或文本数据 | 不可重复的批量数据 | 用key检索value的 数据场景 |
5.9 容器的通用功能
各个容器有不同的功能,但是他们都属于容器,有一些功能是通用的。
例如之前介绍的 len() 函数,以及for循环遍历,各个容器都是支持的。
下面再介绍一下常用的通用的功能方法。
1 max(容器)
max(容器) 函数可以获取容器内最大的元素。
python
my_list = [1, 2, 3, 4, 5]
my_tuple = (1, 2, 3, 4, 5)
my_str = "Hello"
my_set = {1, 2, 3, 4, 5}
my_dict = {1:1*2, 2:2*2, 3:3*2, 4:4*2, 5:5*2}
print(max(my_list))
print(max(my_tuple))
print(max(my_str))
print(max(my_set))
print(max(my_dict))字典类型,会取出key最大的元素。
执行结果:
5
5
o
5
5对应的还有 min(容器) 函数,可以获取容器内最小的元素。
同样还有一些转换的函数,可以实现容器类型的转换:
list(容器)函数:可以将容器转换为列表。
str(容器) 函数:可以将容器转换为字符串。
tuple(容器)函数:可以将容器转换为元组。
set(容器) 函数:可以将容器转换为集合。
2 容器排序
可以使用 sorted(容器, [reverse=True]) 函数,来对指定的容器中的元素进行排序,排序后会得到一个新的列表对象,原容器不变。
[reverse=True]可以省略。
python
my_list = [1, 8, 3, 6]
new_list = sorted(my_list)
print(my_list)
print(new_list)执行结果:
[1, 8, 3, 6]
[1, 3, 6, 8]可以看出原容器是不变的,得到一个新的列表对象。
可以指定 reverse 参数,来实现倒序排列:
python
my_list = [1, 8, 3, 6]
new_list = sorted(my_list, reverse=True)
print(my_list)
print(new_list)执行结果:
[1, 8, 3, 6]
[8, 6, 3, 1]对其他容器类型进行排序:
python
# 对元组进行排序
my_tuple = (1, 8, 3, 6)
new_list1 = sorted(my_tuple, reverse=True)
print(new_list1)
# 对字符串进行排序
my_str = "Hello"
new_list2 = sorted(my_str, reverse=True)
print(new_list2)
# 对集合进行排序
my_set = {1, 8, 3, 6}
new_list3 = sorted(my_set, reverse=True)
print(new_list3)
# 对字典进行排序
my_dict = {1:1*2, 2:2*2, 3:3*2, 4:4*2, 5:5*2}
new_list4 = sorted(my_dict, reverse=True)
print(new_list4)执行结果:
[8, 6, 3, 1]
['o', 'l', 'l', 'e', 'H']
[8, 6, 3, 1]
[5, 4, 3, 2, 1]对字符串进行排序,会讲字符串拆分成一个一个字符进行排序,组成一个列表。
对字典进行排序,是对字典中所有的key进行排序。