Appearance
HTML5教程 - 4 字符编码
4.1 编码和解码
所有的数据在计算机中存储时都是以二进制 0 和 1 的形式存储的,文字图片都不例外。
那我们为什么能看到文字呢?
这是因为在存储文字的时候,都需要转换为二进制码(0 和 1)进行存储。当我们读取这段文字时,计算机会将二进制编码转换为字符,供我们阅读。
所以这里涉及到两个步骤:编码 和 解码。
编码 :将字符转换为二进制码的过程称为编码。
解码 :将二进制码转换为字符的过程称为解码。
4.2 字符集
但是将二进制和文字之间编码和解码遵循什么规则呢?这里就会用到字符集。
计算机是美国人发明的,美国人的文字也就是大小写字母+数字+一些符号就完事了,满打满算100多个,够用了。他们就整了一个 ASCII 码,如下:
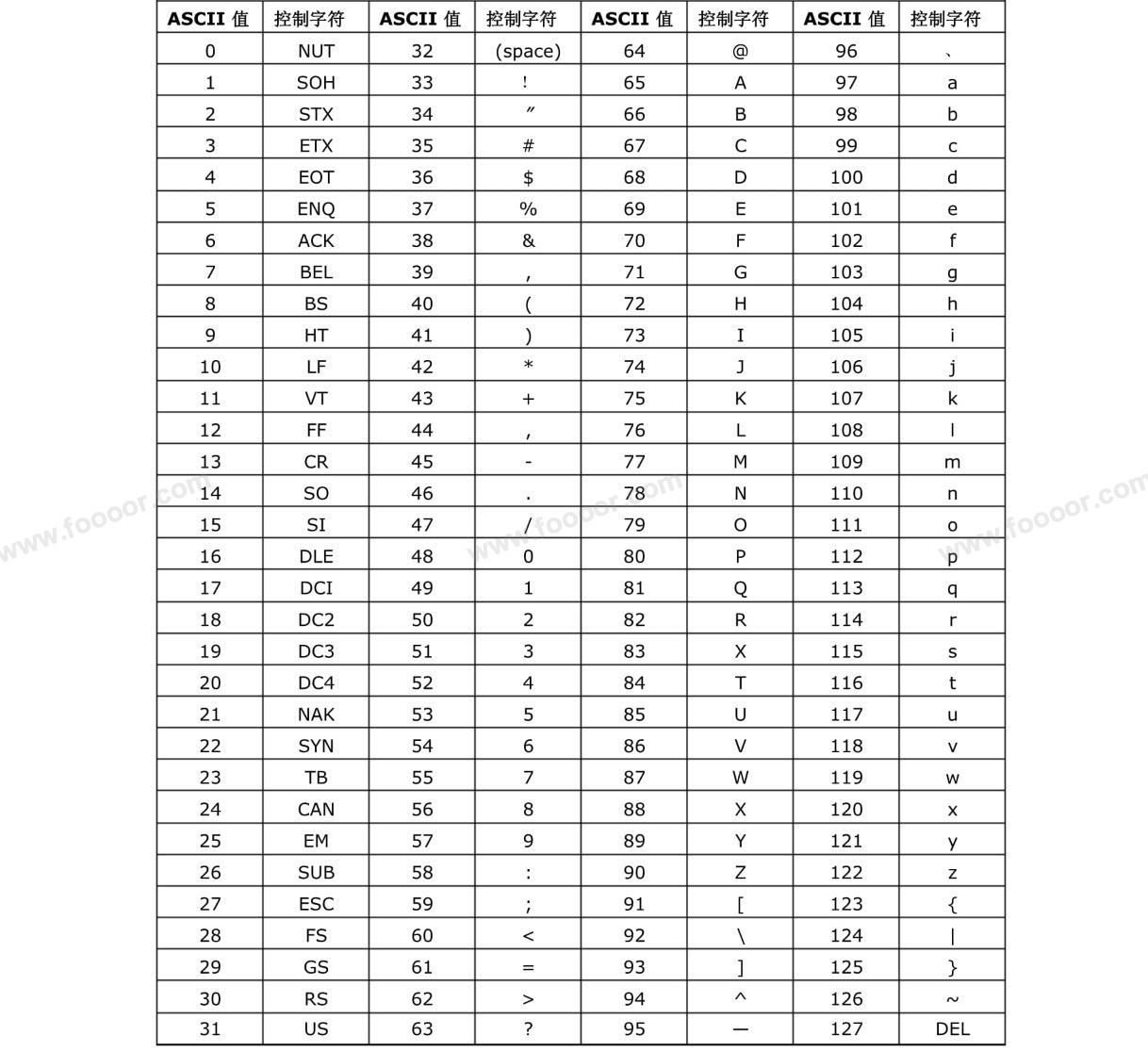
ASCII码叫美国信息交换标准代码,规定了对应二进制数字对应的文字(上面 ASCII 值使用的十进制表示),总共 128 个。从上图可以看到 a 对应的数字是 97 ,也就是二进制的 97 表示字母 a。
但是美国人使用计算机,欧洲人也要使用计算机啊,但是欧洲的语言128个字符满足不了啊,因为包括罗马字母和符号等,于是欧洲搞了一个 ISO-8859-1(当然还有一些其他的字符编码)。
中国也要用计算机啊,这些编码都不行,我们搞了一个 GB2312 的字符编码,包括 6763 个常用汉字和 682 个字符,但是不包括生僻字和中文繁体,后来由搞了一个 GBK,支持 20000+ 汉字,支持繁体中文。
但是世界上的语言太多了,字符集也太多了,有没有一个字符集支持世界上所有的语言呢?有的!
它就是 UTF-8 (大小写均可),utf-8 字符集是万国码,包含所有语言文字和符号,我们以后使用 UTF-8 字符编码就好了。
4.3 乱码问题
如果我们保存文档用的字符编码和读取文档用的编码不是一个编码,就会出现乱码问题。
举个栗子:
使用 VSCode 新建一个文本文件:
编写一段文字,然后选择使用指定的字符编码进行保存:
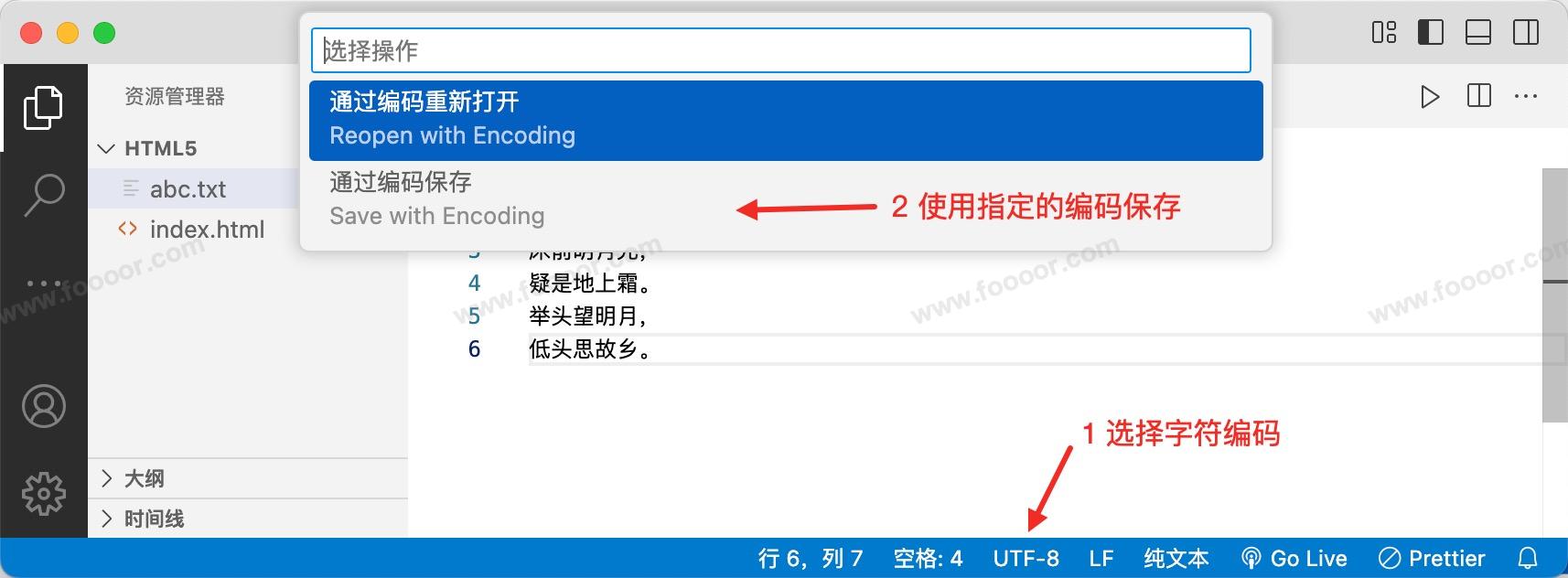
可以选择 GBK 编码进行保存(VSCode 默认是 UTF-8 编码):
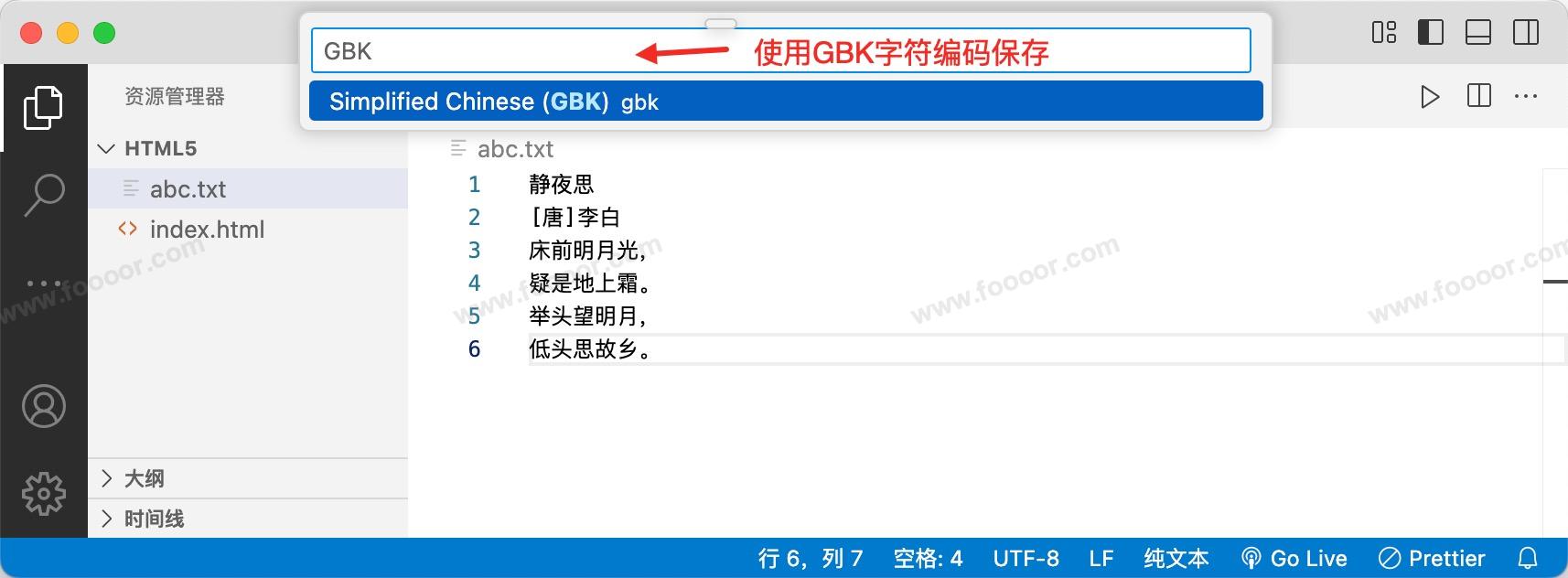
关闭 VSCode,重新使用 VSCode 打开保存的文件(不关闭会有缓存),会发现之前的文档乱码了,因为打开的时候,默认是使用 UTF-8 字符编码打开。
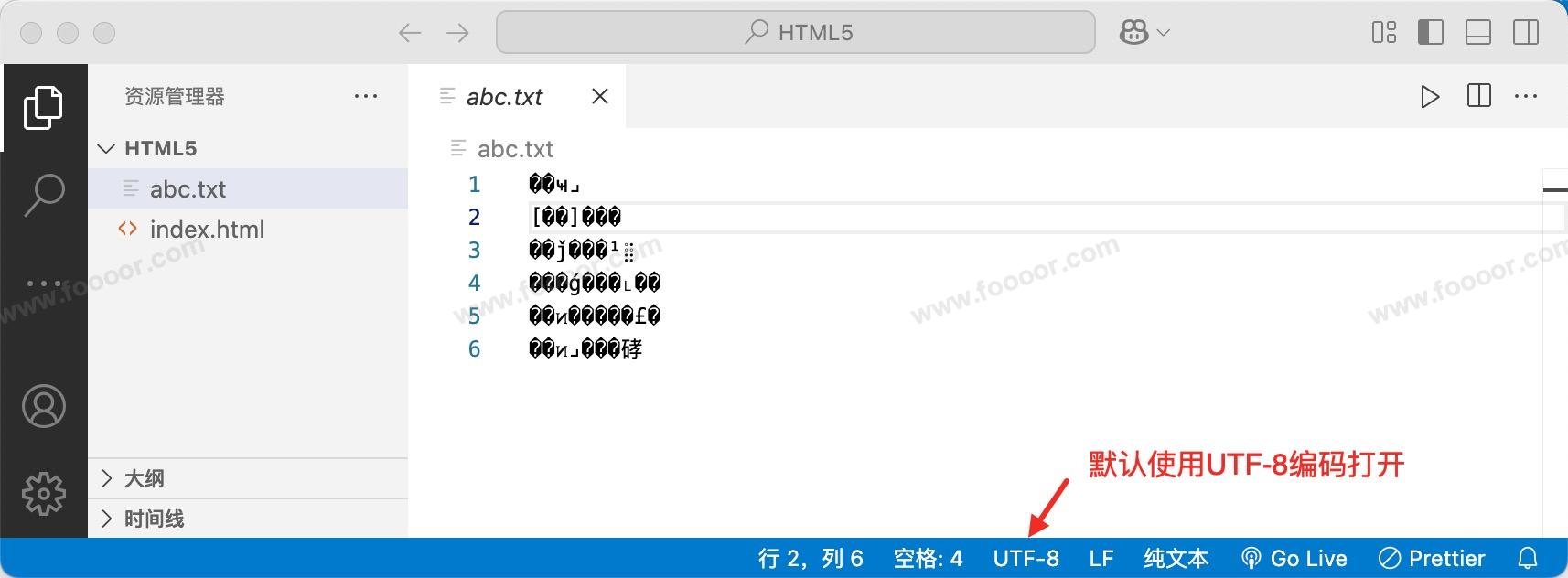
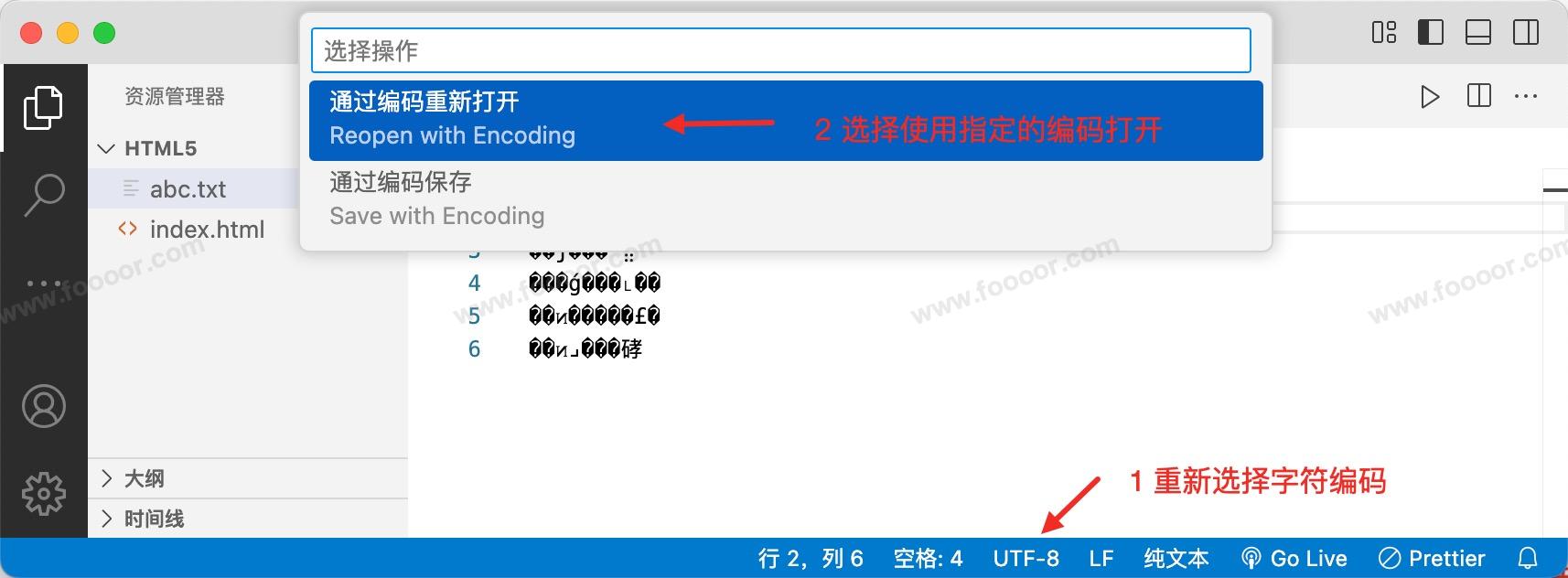
怎么办呢?此时还有救,因为我们编写的是中文,保存的时候使用的是 GBK 保存的,只需要重新使用 GBK 编码打开就可以了:
修改使用 GBK 打开后,文档又正常显示了。
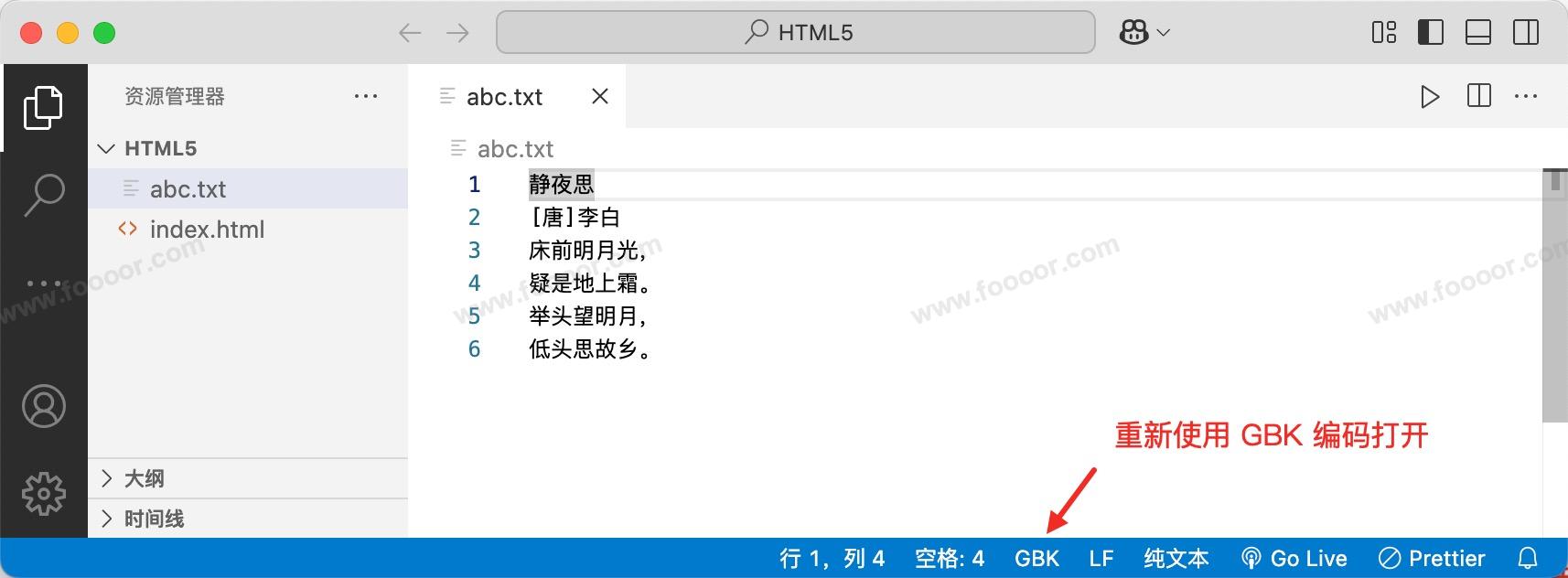
但是但是!!!需要注意,我们刚才编写的是中文,保存使用的是 GBK 进行保存,GBK 是支持中文的,所以保存是成功的,使用对应的字符编码读取就可以了。但是如果我们编写了中文,然后使用 ISO8859-1 字符编码进行保存,那完蛋了,因为 ISO8859-1 字符编码是不支持中文的,所以在保存的时候每个字符是找不到对应的二进制编码的,保存的就是一个 ?,所以文档没有成功保存!!!保存以后,使用任何的编码都无法读取文档的内容了!
也就是说,保存文档的时候,一定要选择支持文档内容的编码进行保存,只要保存成功了,选择对应的编码读取就可以了。即使使用了不对的编码打开,也只是乱码而已,文档的内容不会丢。但是如果保存的字符编码不支持保存的内容,那完犊子了,你内容就没有成功,切记切记!!!
下面是使用 ISO8859-1 保存中文后的效果:
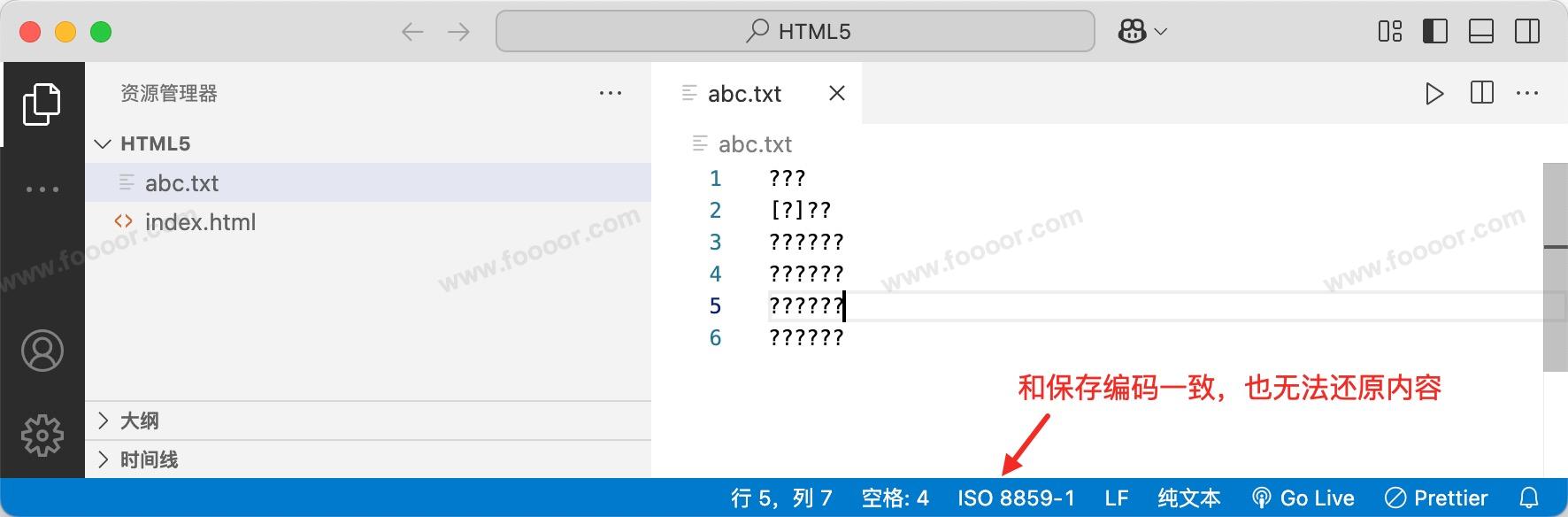
当然,我们以后使用 UTF-8 编码就可以了,保存和读取都使用 UTF-8,没毛病!
在编写 HTML 文件的时候,使用 UTF-8 字符编码进行保存,然后通过 meta 标签来设置网页的字符集,让浏览器使用 utf-8 字符集来进行解析,避免乱码问题。
html
<meta charset="utf-8" />