Appearance
LangChain教程 - 3 大模型本地部署
在上一个章节简单介绍了使用 Python 代码调用阿里云百炼平台的大模型,也就是调用被人提供的大模型。
下面我们就在自己的电脑上,通过Ollama 部署一个参数和体积较小的模型,Ollama 是在本地运行大模型的一个工具,通过 Ollama 我们可以选择自己喜欢的大模型去运行,毕竟现在的模型太多了,例如 deepseek、千文qwen 等等。
模型在使用上区别不大,参数大的模型聪明一些、逻辑推理能力更强而已。而小参数模型更轻便,适合我们电脑配置一般、追求部署速度和轻量化使用的场景。
3.1 搭建的步骤
在开始搭建大模型之前,我们需要了解一下整个搭建过程的大体步骤。无论使用哪种工具,搭建大模型的基本流程都差不多:
- 安装运行大模型的工具:下载并安装运行大模型的工具,这里选择 Ollama;
- 下载模型:通过运行工具 Ollama 下载你需要的大模型;
- 启动模型:启动模型并进行测试,确保它能正常运行;
- 使用模型:通过API或命令行与模型进行交互,使用它来完成各种任务。
3.2 常用工具介绍
现在市面上有很多工具可以用来在本地运行大模型,其中比较流行的有 Ollama、LM Studio 和 llama.cpp。
让我们来了解一下这些工具的作用和特点:
1 Ollama
Ollama是一个专为本地运行大模型设计的工具,它的特点是简单易用,支持多种模型格式,并且提供了友好的命令行界面。
主要功能:
- 支持多种主流大模型,如Qwen、LLaMA、Mistral、Gemini等
- 提供简单的命令行接口,方便用户下载和运行模型
- 内置模型量化功能,可以根据硬件条件自动调整模型精度
- 支持API调用,可以与其他应用程序集成
- 跨平台支持(Windows、macOS、Linux)
2 LM Studio
LM Studio是一个图形化的大模型运行工具,它的特点是界面友好,适合不太熟悉命令行的用户。
主要功能:
- 提供直观的图形界面,方便用户管理和运行模型
- 支持多种模型格式,如GGUF、GPTQ等
- 内置模型浏览器,可以直接在界面中浏览和下载模型
- 支持实时调整模型参数,如温度、top-k等
- 支持API调用和本地Web界面
3 llama.cpp
llama.cpp是一个用C++编写的大模型推理库,它的特点是轻量级、高性能,适合在资源有限的设备上运行大模型。
主要功能:
- 高度优化的推理代码,运行速度快
- 支持模型量化,可以大幅减少模型大小和内存使用
- 支持多种硬件加速,如CPU、GPU、NPU等
- 提供命令行接口和API
- 跨平台支持,甚至可以在树莓派等嵌入式设备上运行
3.3 使用Docker部署Ollama
这里就选择 Ollama 进行大模型部署,主要原因如下:
- 简单易用:Ollama的命令行接口非常简单,只需要几个命令就可以完成模型的下载和运行,对新手非常友好。
- 模型丰富:Ollama支持多种主流大模型,并且会定期更新模型库,用户可以方便地获取最新的模型。
- 性能优化:Ollama内置了模型量化和硬件加速功能,可以根据用户的硬件条件自动调整,最大化模型的运行性能。
- API支持:Ollama提供了RESTful API,可以方便地与其他应用程序集成,扩展性强。
- 跨平台:Ollama支持Windows、macOS和Linux等多种操作系统,用户可以在不同的设备上使用相同的命令和流程。
Ollama官网 (https://ollama.com/)。
为了更方便地搭建和管理 Ollama,这里我使用 Docker 进行部署,部署方便而且与主机系统隔离,如果你不想使用 Docker 部署,查看官网,也是一行命令就搞定安装。
Docker是一种容器化技术,可以将应用程序及其依赖项打包成一个独立的容器,方便在不同的环境中运行。如果不了解,可以学习本站的 Docker基础教程 。
下面使用 Docker 进行部署。
1 下载Ollama镜像
首先使用 Docker 下载 Ollama 容器镜像:
bash
docker pull ollama/ollama2 运行Ollama容器
使用以下命令来运行Ollama容器:
bash
docker run -d -v /Users/foooor/docker/my-ollama:/root/.ollama -p 11434:11434 --name my-ollama ollama/ollama这个命令的含义是:
-d:后台运行容器;-v /Users/foooor/docker/my-ollama:/root/.ollama:将容器中的/root/.ollama目录挂载到本地的/Users/foooor/docker/my-ollama,用于持久化存储模型和配置;-p 11434:11434:将容器的11434端口映射到主机的11434端口,用于API访问;--name my-ollama:给容器命名为my-ollama;ollama/ollama:使用官方的Ollama镜像;
现在 Ollama 容器已经运行起来了,但是现在还没有运行大模型,我们需要下载模型然后运行。
3.4 运行大模型
下面使用 Ollama 下载和运行大模型。
1 搜索模型
可以访问 Ollama 的模型仓库,Ollama模型仓 (https://ollama.com/library)
根据需要选择自己想要的模型。
例如这里我选择 qwen3 的模型,搜索以后,进入模型详情页,会显示模型的不同参数版本:
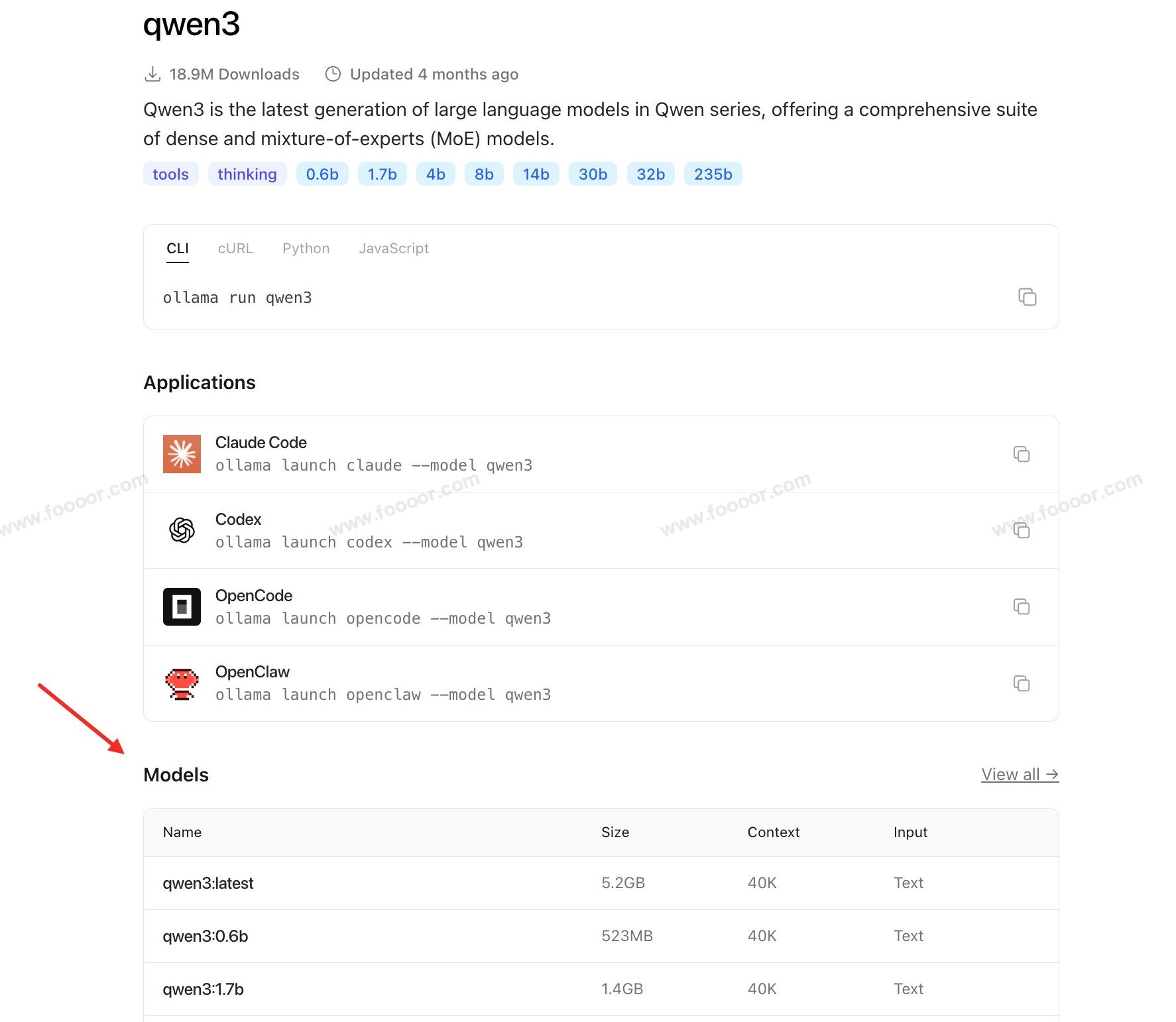
下面是几个最适合入门的小模型(体积小、运行快、不卡):
| 模型名称 | 参数大小 | 下载体积 | 特点 |
|---|---|---|---|
| qwen:0.5b | 0.5B | 418MB | 通义千问最轻量版,中文友好 |
| phi3:mini | 3.8B | 528MB | 微软出品,推理快,英文好 |
| gemma:2b | 2B | 1.4GB | Google 出品,平衡性能和体积 |
| mistral:7b-instruct-v0.2 | 7B | 4.1GB | 性价比高,比 llama3:8b 小 |
- qwen3 是 qwen 的后续更新版本。
怎么确认模型能不能在自己电脑上跑?
- 轻量模型(0.5B/1.8B):只要你的电脑有 2GB 以上内存,就能流畅运行(不用 GPU,纯 CPU 就行);
- 中等模型(7B):需要 8GB 以上内存;
- 大模型(13B+):建议 16GB 以上内存,或有 GPU 加速。
2 下载模型
其实我们可以直接运行模型,会自动下载的。我们也可以先下载模型,然后运行模型,这样更清晰一些。
我们使用 docker exec 命令和 Ollama 下载 qwen3 的模型:
bash
# 仅下载qwen3:1.7b模型,不启动对话
docker exec -it my-ollama ollama pull qwen3:1.7b- 这个命令会让
my-ollama容器下载qwen3:1.7b模型,你也可以替换为其他模型或选择更大的参数,如mistral、gemma、llama等。 - 如果不是容器,直接运行
ollama pull qwen3:1.7b就可以了。
3 运行模型
你可以不运行上面的下载模型命令,直接运行下面的命令也是可以的,会自动下载模型,然后运行模型:
bash
docker exec -it my-ollama ollama run qwen3:1.7b- 这个命令会下载,然后启动
qwen3:1.7b模型,并进入交互模式,你可以直接在命令行中与模型对话。
可以直接在终端中进行对话了:

你就说简单不简单,棒不棒吧!
4 退出对话
在上面的终端中,输入 /bye 可以退出命令行对话,但模型本身不会退出后台(Ollama 服务仍在容器内运行),只是结束了当前的对话会话而已。
可以重新通过运行 docker exec -it my-ollama ollama run qwen3:1.7b 命令进行交互对话。
3.5 调用大模型
现在大模型现在已经跑起来了,上面是通过终端来交互的。但是一般我们都会通过 API 和大模型进行交互,对外提供接口服务。
下面介绍一下如何通过 API 来访问大模型。
Ollama 容器运行后,会在 http://localhost:11434 提供 API 服务。你可以使用 curl 或其他 HTTP 客户端来调用 API。
1 使用curl访问API
直接在终端运行 curl 命令,调用接口:
bash
curl http://localhost:11434/api/generate -d '{
"model": "qwen3:1.7b",
"prompt": "你好"
}'- 因为接口是流式返回的,所以会一直不停的返回信息。
2 使用Apifox访问API
也可是使用一些工具类访问,例如 Apifox 或 Postman,发起 POST 请求:
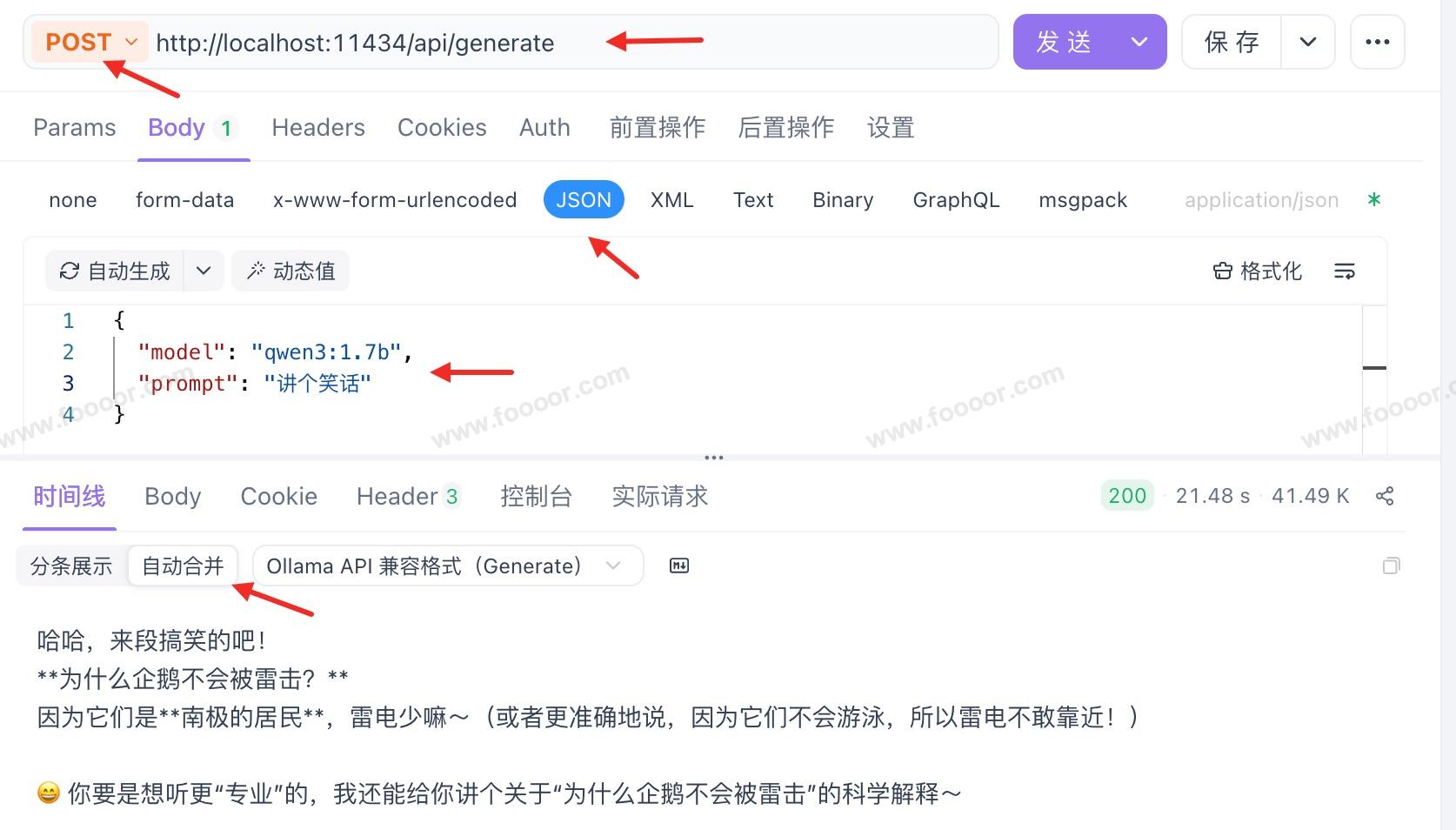
- Apifox 可以将结果自动合并,因为模型有思考过程,所以反馈结果有点慢。
这种 API 的访问方式只是测试,因为Ollama 本身没有内置 API Key / 鉴权功能,所以谁都能访问,正常在生产环境,我们需要自己添加「中间层」来实现访问控制,核心逻辑是:
用户请求 → 带鉴权的中间服务 → 验证通过后转发给Ollama → 返回结果给用户3.6 非Docker容器部署
其实使用容器部署很简单,而且和主机有隔离,还可以限制容器的性能。
如果你想在主机上部署,也是很简单的,官网上就给出了一条命令,即可安装,
bash
curl -fsSL https://ollama.com/install.sh | sh下面罗列了一些命令,简单看一下:
sql
# 安装
curl -fsSL https://ollama.com/install.sh | sh
# 查看ollama版本
ollama --version
# 安装后,Ollama 服务默认会后台启动;若未启动,可以手动执行如下命令启动服务
ollama serve
# 拉取(下载)模型
ollama pull qwen3:1.7b
# 运行模型(自动下载 + 启动),出现 >>> 提示符即可开始对话
ollama run qwen3:1.7b- 也是非常的简单的,上面 docker 运行命令只是运行容器内的 ollama 命令,所以将前面的
docker exec -it my-ollama忽略即可。
好了,这个章节我们已经在本地部署了大模型了,并且可以在终端中对话了,后面我们也可以使用代码访问我们自己部署的模型。