Appearance
LangChain教程 - 6 LangChain与RAG
6.1 LangChain简介
LangChain 是一个专门用来开发 大模型应用(LLM Applications) 的框架。它帮我们把开发 AI 应用时常见的一些能力封装好了,让我们不用从零开始写所有东西,而是可以直接使用现成的组件。
可以把 LangChain 想象成一套 AI 开发工具箱。里面已经准备好了很多工具,比如:
- 调用大模型
- 管理提示词
- 处理文档
- 连接向量数据库
- 实现对话记忆
- 构建多步骤的 AI 工作流程
开发者只需要把这些组件组合起来,就可以很快搭建出一个完整的 AI 应用。
很多时候,一个 AI 的回答并不是一步完成的,而是一个流程。
举个简单的例子:
用户提问 → 检索相关资料 → 把资料交给模型 → 模型整理答案 → 返回结果在 LangChain 里,这样的流程可以被组织成一条“链”。数据会从前一个步骤流向后一个步骤,最后得到结果。所以 LangChain 这个名字其实也很好理解,它的意思就是 把不同的 AI 能力“链”在一起。
6.2 LangChain的主要功能
LangChain 的核心思想其实很简单:把开发大模型应用时常见的能力模块化。这样开发者就不用每个功能都自己实现,而是可以直接使用这些模块,再把它们组合起来构建 AI 应用。
下面简单看一下 LangChain 中最常见的几个核心功能。
1 Prompts(提示词管理)
在真实项目中,Prompt 往往不仅仅是一句话,还可能包含角色设定、背景信息、示例、输出格式以及动态变量等内容。
LangChain 提供了 Prompt 模板机制,可以把提示词结构化管理,例如在模板中定义变量,然后在运行时动态填充数据。这样不仅代码更清晰,也方便做提示词优化和复用。
2 Models(模型调用)
现在可用的大模型非常多,比如 OpenAI、通义千问、Claude、各种本地模型等等。如果每个模型都有不同的调用方式,代码会非常混乱。
LangChain 提供了统一的模型调用接口,让不同模型的调用方式保持一致。这样在需要更换模型时,通常只需要修改配置,而不需要重写整个业务逻辑。
3 Memory(会话记忆)
大模型本身并没有真正的“长期记忆”。每次对话时,如果希望模型记住之前的聊天内容,就必须把历史记录重新发送给模型。
LangChain 提供 Memory 模块,可以自动管理聊天历史,比如保存对话记录、控制历史长度、或者对旧内容进行摘要压缩,从而实现看起来像“长期会话”的效果。
4 Documents(文档处理)
很多 AI 应用需要读取外部数据,比如企业文档、本地资料、网页内容等。LangChain 提供了各种 文档加载器(Document Loader),可以读取不同类型的数据,并转换成统一的文档格式,方便后续处理。
5 Text Splitter(文本切分)
大模型的上下文长度是有限的,因此长文档通常需要先拆分成多个小段。
LangChain 提供文本切分器,可以按照长度、段落或语义规则,把长文本拆分成很多小块,这一步通常是做知识库或 RAG 系统时的基础步骤。
6 Embeddings(向量化)
为了实现语义检索,需要把文本转换成向量。LangChain 提供统一的 Embedding 接口,可以对接不同的向量模型,把文本转换成向量表示。
7 Vector Store(向量数据库)
当文本被转换成向量之后,就可以存入向量数据库中,用来做相似度检索。LangChain 可以对接很多常见的向量数据库,比如 Chroma、FAISS、Milvus 等,从而实现语义搜索能力。
8 Chains(链式流程)
在真实应用中,一个问题往往不是一步完成的,而是一个流程,比如先检索资料,再调用模型生成答案。
LangChain 提供 Chain 机制,可以把多个步骤串联起来,形成一个完整的执行流程。这也是 LangChain 这个名字的来源。
9 Agents(智能体)
在更复杂的场景中,模型可能需要根据问题自动选择工具,比如查询数据库、调用 API、或者执行代码。
LangChain 提供 Agent 机制,让模型可以动态决定下一步该做什么,从而构建更智能的 AI 应用。
6.3 RAG简介
你有没有遇到过这样的问题:当你问 AI 一些专业问题或最新信息时,它可能会给出错误的回答,
例如:
>>> 美国总统现在是谁
目前(2024年5月16日)的美国总统是 **乔·拜登**。
你可以通过以下方式查看最新信息:
* **美国总统官方网站:** [https://www.whitehouse.gov/](https://www.whitehouse.gov/)
* **新闻媒体:** 搜索“美国总统”会看到最新的新闻报道。大模型一开始出来的时候,会存在上面的问题,特朗普当上总统了,而大模型依然会回答拜登。当然现在线上的大模型,因为联网了,有了相关的处理,所以可以回答了。
但是本地部署的大模型还是会有这个问题,这是因为大模型虽然知识渊博,但它也有两个明显的缺点:
大模型的训练数据有一个截止日期,它不知道截止日期之后发生的事情;
企业内部的资料、私有文档、产品手册等,这些内容模型本身是完全不知道的。
为了解决这些问题,RAG(Retrieval-Augmented Generation,检索增强生成) 技术应运而生。
简单来说,RAG 的核心思想是:在大模型生成回答之前,先从外部数据源中检索相关信息,然后将这些信息与用户的问题一起发送给大模型,让大模型基于这些最新、最相关的信息生成回答。
换句话说,RAG 相当于给大模型增加了一个“查资料”的能力。
举个简单的例子:
假设你做了一个公司内部知识库,里面包含产品文档、技术文档和各种说明资料。当用户问一个问题时,系统会先在知识库中找到最相关的几段内容,然后把这些内容交给大模型,再由模型整理成自然语言回答用户。这样得到的答案不仅更准确,而且还能引用企业内部的真实信息。
这也是为什么很多 企业知识库问答系统、文档问答系统、客服机器人 都会采用 RAG 架构。
6.4 RAG 的实现流程
让我们通过一个例子来理解 RAG 的工作原理:
RAG 的基本流程可以分为以下几个步骤:
数据准备:
首先要做的是读取各种文档,比如 PDF、CSV、网页内容或者本地文件。因为文档通常比较长,所以需要把它们拆分成很多小段,并将信息转换为向量数据保存到数据库中
检索: 接收用户的问题后,将问题转换为向量(embedding),然后到向量数据库中查找与问题最相关的信息,返回检索到的相关信息
生成: 将用户的问题和检索到的相关信息一起发送给大模型,大模型基于这些信息生成回答,返回最终的回答给用户。
通过一个流程图来看一下:
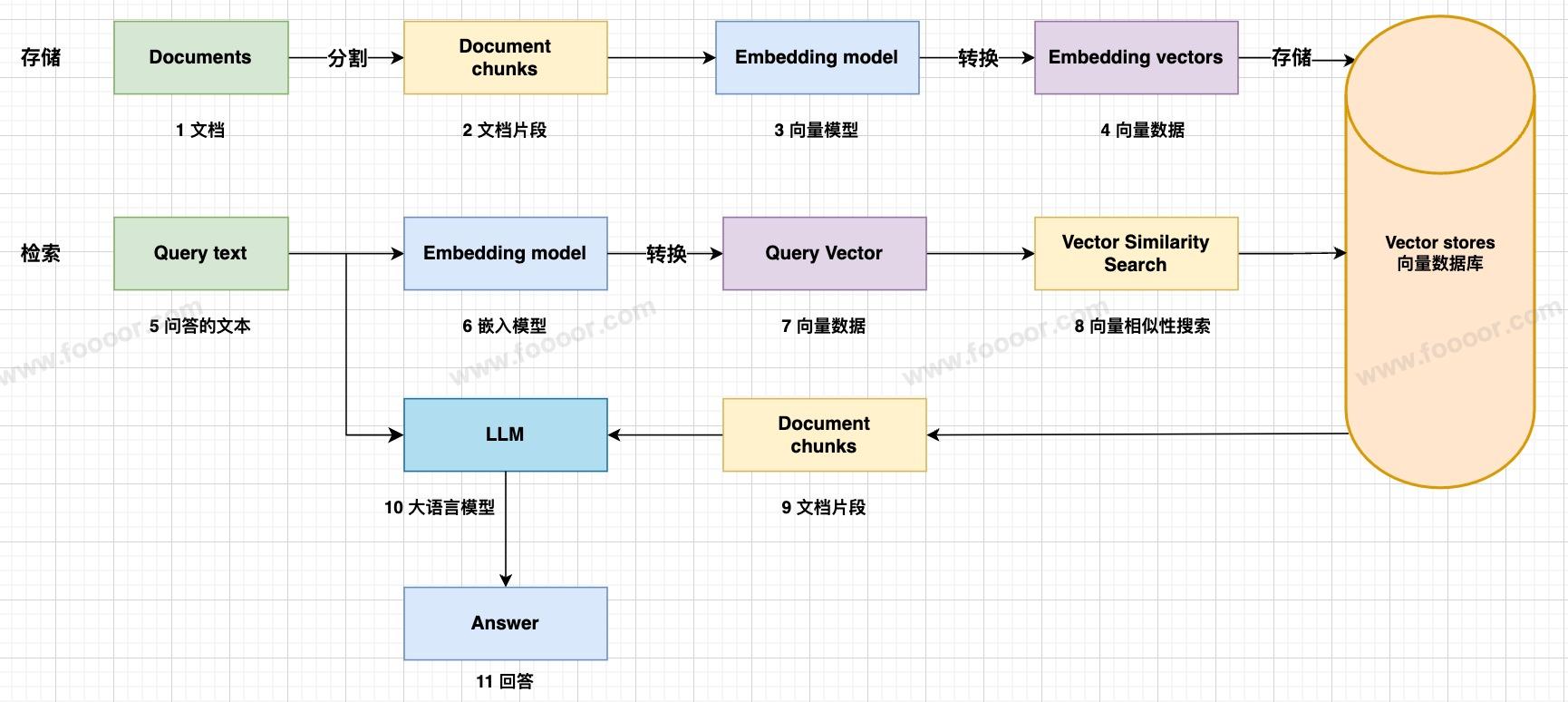
在 LangChain 中,我们可以很方便地实现这一整套流程。例如使用 Document Loader 读取文档,使用 Text Splitter 切分文本,使用 Embedding 生成向量,再把向量存入 Vector Store。当用户提问时,通过 Retriever 检索相关内容,然后结合 Prompt 和 模型(Model) 生成最终答案。
可以看到,RAG 并不是一个单独的技术,而是一种 把文档检索和大模型结合起来的应用架构。而 LangChain 提供的这些模块,正好可以帮助我们非常方便地搭建完整的 RAG 系统。
对于大模型而言,本质就是用户给出输入,模型给出输出,用户能做的有限,只能在输入上下功夫,把提示词给足。所以 RAG 就是在向模型提问之前基于已有的知识库或文档内容做检索,然后将更精准的内容和足够的信息提供给模型,让模型基于提供的信息给出更好的输出。
在接下来的内容里,我们先会介绍 LangChain 的各个主要功能,最后使用 LangChain 动手实现一个完整的 RAG 项目,从读取文档开始,一直到最终实现一个可以回答问题的知识库助手。