Appearance
LangChain教程 - 13 RAG项目
前面介绍了,对于一个 RAG 项目,主要的流程如下:
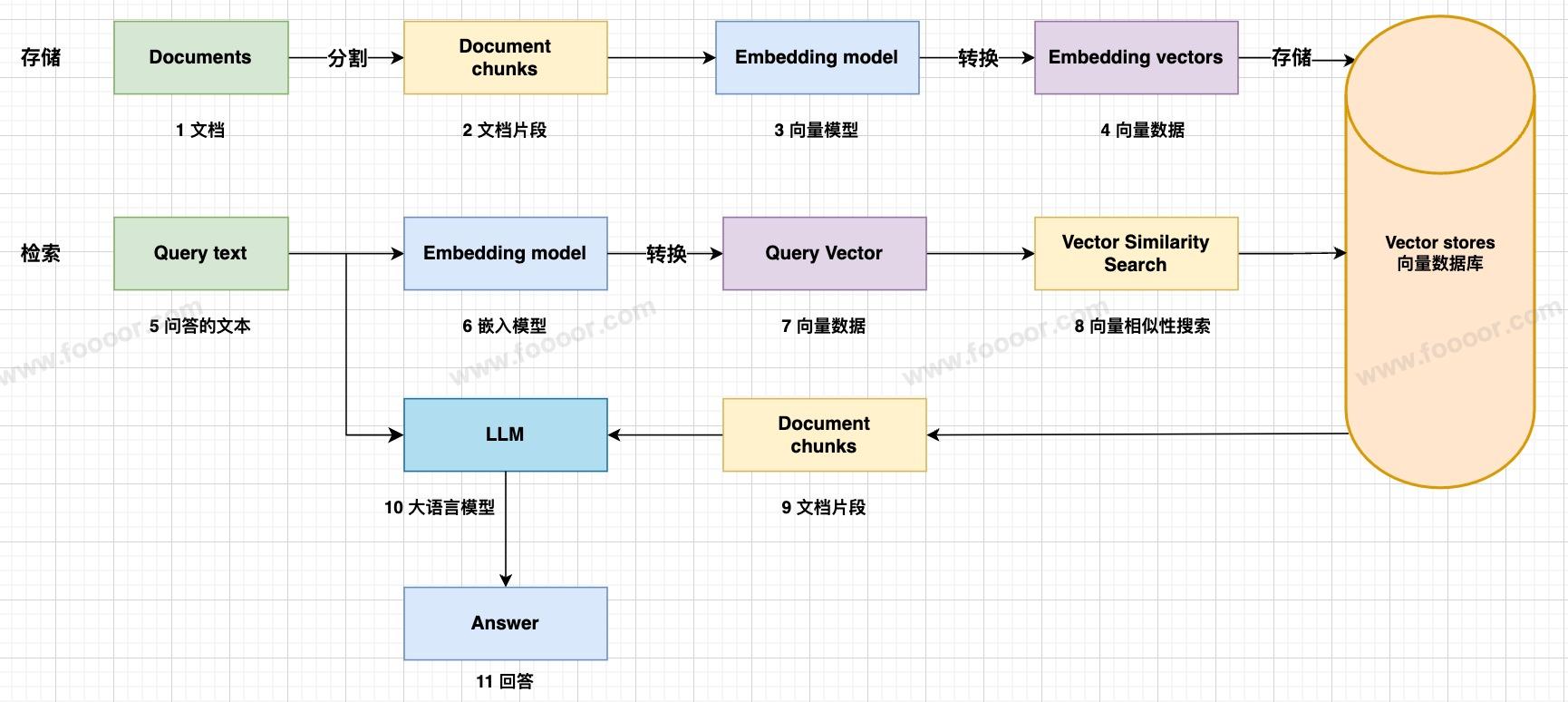
上面的每一个步骤的操作我们在前面都学习了,包括文档加载、文本分割、向量存储、检索增强生成等功能。下面通过一个简单的项目,将所有的操作串起来,使用 Streamlit 构建一个完整的 RAG 项目。
13.1 创建项目
首先创建一个 Python 项目,然后安装相关的依赖:
bash
# 安装langchain相关的依赖
pip install langchain langchain-community langchain-ollama dashscope chromadb langchain-chroma
# 安装streamlit
pip install streamlitStreamlit是一个快速构建 Web 应用的 Python 库,待会使用它快速构建页面。
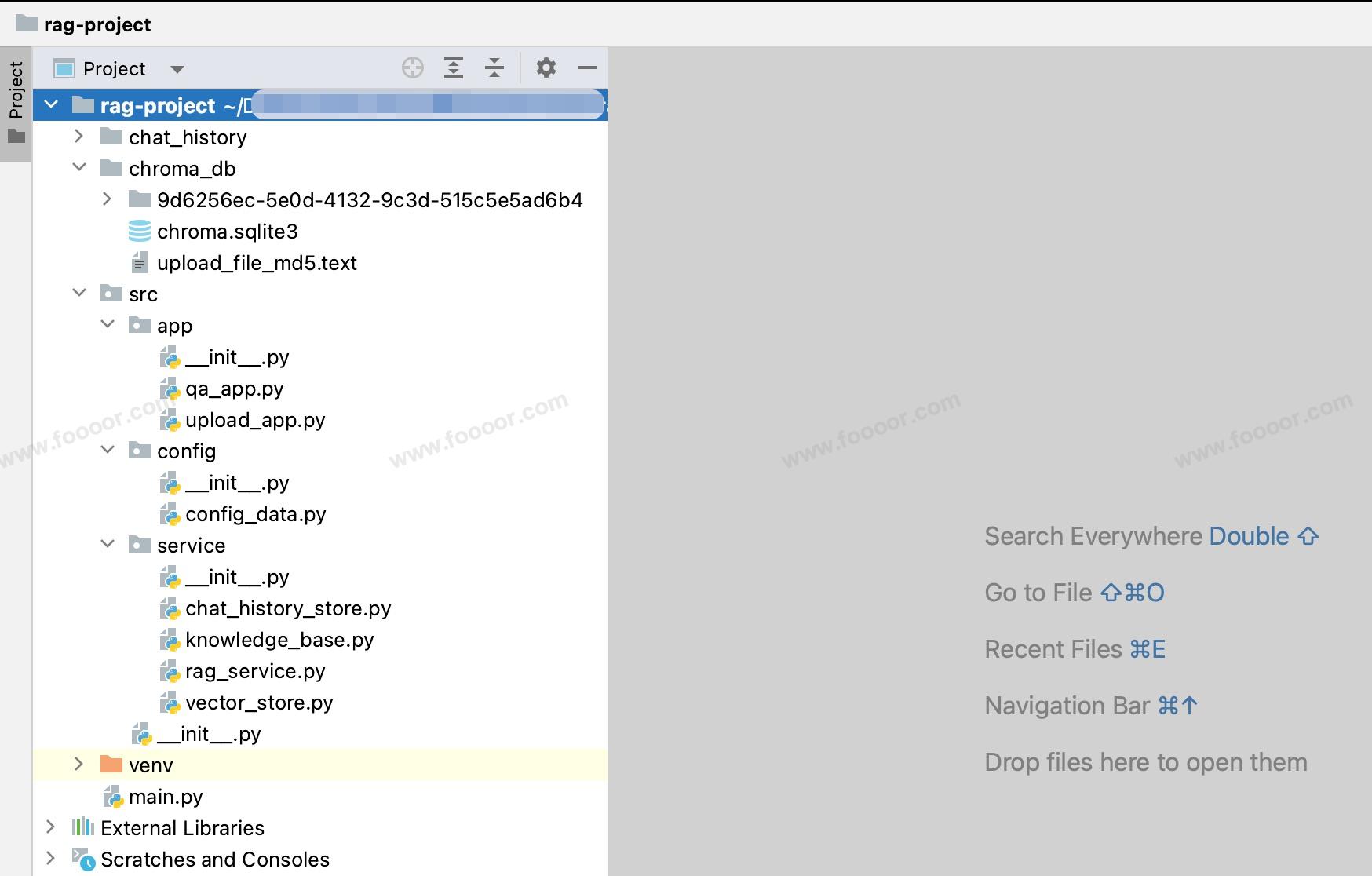
右键项目 --> New --> Python Package,在项目下创建一个 src 包,后面将源代码放到 src 目录下。
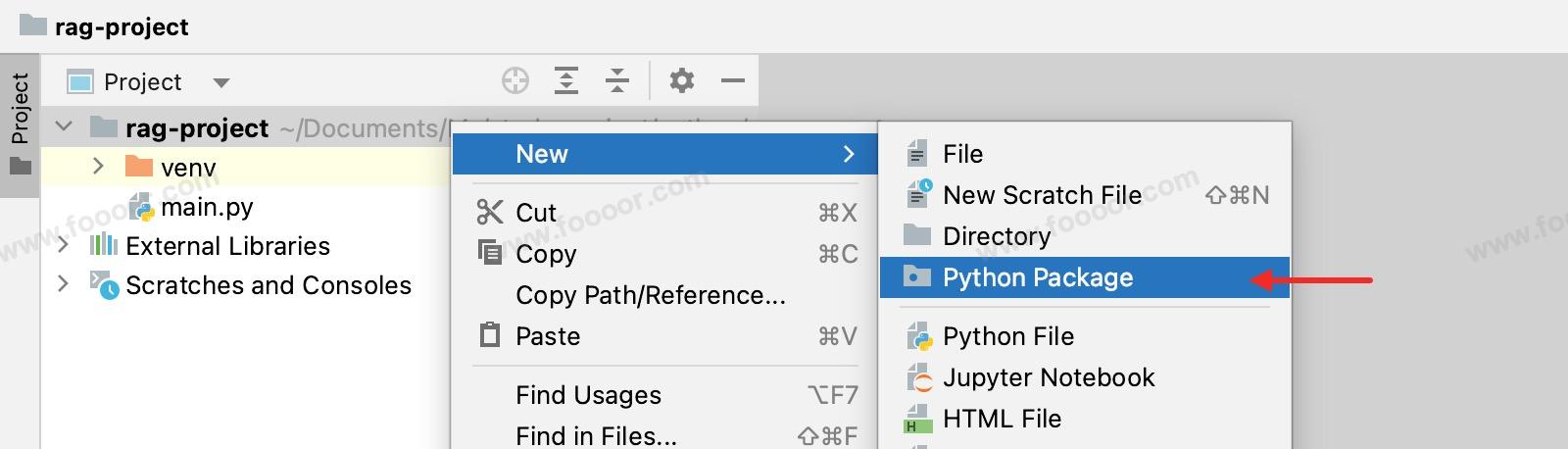
右键 src 下创建多个 Python Package 包,用来放不同文件:
app:放启动项目的文件的包,后面运行项目,会运行两个页面,一个是用来上传文件到知识库,一个是用户问答的页面;config:放配置文件的包,这里直接使用 python 文件来定义一些常量,在其他的文件中引入使用,例如使用的模型名称等;service:放处理功能service的包;
项目的主要结构如下:
13.2 创建配置文件
在 config 包下创建 config_data.py ,内容如下:
python
"""项目配置文件"""
from pathlib import Path
def get_project_root_path():
"""获取项目根目录路径"""
project_root_path = Path(__file__).resolve().parents[2]
return project_root_path
# Chroma 向量数据库配置
PERSIST_DIRECTORY = get_project_root_path() / "chroma_db" # 向量文件所在目录
COLLECTION_NAME = "goods_info" # 集合名称,相当于表名
# MD5文件路径,用于存储已处理文件的MD5值
MD5_FILE_PATH = PERSIST_DIRECTORY / "upload_file_md5.text"
# 历史记录保存目录
CHAT_HISTORY_DIR = get_project_root_path() / "chat_history"
# 最大历史消息数量
MAX_HISTORY_MESSAGES = 20
# 文本分割配置
CHUNK_SIZE = 1000 # 每个文本块的大小
CHUNK_OVERLAP = 100 # 文本块之间的重叠大小
SEPARATORS = ["\n\n", "\n", "。", ".", "!", "!", "?", "?", " "] # 分割符
MAX_SPLIT_CHAR_NUMBER = 1000 # 最大分割字符数
# 相似度阈值,控制返回的匹配文档数量
SIMILARITY_THRESHOLD = 2
# 模型配置,指定模型名称
EMBEDDING_MODEL_NAME = "qwen3-embedding:0.6b" # 嵌入模型名称
CHAT_MODEL_NAME = "qwen3:1.7b" # 聊天模型名称
# 用户配置
USER_ID_001 = "user_001"
SESSION_CONFIG = {"configurable": {"session_id": "user_001_session_001"}}- 配置文件中主要是一些常量的配置,包括向量文件的存储目录、聊天记录的存储目录;
- 我们需要将文本数据转换为向量数据存储到向量数据库,但是如果多次存储相同的文本到向量数据库,会造成数据的冗余和存储空间的浪费,所以我们在上传之前,计算文本的 md5 值,通过 md5值 判断该文本有没有被上传过,如果没有被上传过,则上传,并将文本的 md5 值记录到文件中。如果上传的时候,在文件中找到相同的 md5 值,则说明被上传过,则不处理了。这里简单使用文件记录 md5 值,生成环境应该使用数据库进行记录。
- 另外这里没有做用户处理,这里简单写死用户的信息。
13.3 向量存储
在 service 包下新建 vector_store.py,主要功能是将文本内容转换为向量存储到向量数据库。
内容如下:
python
"""向量存储服务模块"""
from typing import List
from langchain_chroma import Chroma
from langchain_core.documents import Document
from langchain_ollama import OllamaEmbeddings
from src.config import config_data as config
# 创建全局的嵌入模型实例
EMBEDDING = OllamaEmbeddings(
model=config.EMBEDDING_MODEL_NAME
)
# 创建全局的向量存储实例
VECTOR_STORE = Chroma(
collection_name=config.COLLECTION_NAME,
persist_directory=config.PERSIST_DIRECTORY,
embedding_function=EMBEDDING
)
class VectorStoreService(object):
"""向量存储服务类,用于管理和检索向量数据"""
def __init__(self):
"""初始化向量存储服务"""
self.embedding = EMBEDDING
self.vector_store = VECTOR_STORE
def get_retriever(self):
"""获取检索器,用于从向量存储中检索相关文档
返回值:
检索器对象
"""
return self.vector_store.as_retriever(
search_kwargs={"k": config.SIMILARITY_THRESHOLD}
)
def add_texts(self, texts: List[str], metadatas: List[dict] = None):
"""添加文本到向量存储
参数:
texts: 文本列表
metadatas: 元数据列表,与文本列表一一对应
返回值:
文档ID列表
"""
return self.vector_store.add_texts(
texts=texts,
metadatas=metadatas
)
if __name__ == "__main__":
# 测试向量存储
service = VectorStoreService()
service.add_texts(["智能手表 Pro 的官方售价是多少?智能手表 Pro 的官方售价为¥1999"], metadatas=[{"source": "test"}])
# 测试向量存储服务
retriever = service.get_retriever()
doc: List[Document] = retriever.invoke("智能手表 Pro 的官方售价是多少")
print(doc)VectorStoreService类主要提供两个方法,一个是将文本内容存储到向量数据库,一个是获取检索器对象,返回的检索器对象,后面用于加入到执行链。
13.4 历史记录存储
在 service 包下新建 chat_history_store.py,主要功能是实现对话历史记录的存储和获取。
内容如下:
python
"""聊天历史存储模块"""
import json
import os
from pathlib import Path
from typing import List
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.messages import BaseMessage, messages_from_dict, messages_to_dict
from src.config import config_data as config
# 从文件中获取会话历史记录
def get_session_history(session_id: str):
"""获取聊天历史对象
参数:
session_id: 会话ID
返回值:
LimitedFileChatMessageHistory: 聊天历史对象
"""
return LimitedFileChatMessageHistory(session_id=session_id)
class LimitedFileChatMessageHistory(BaseChatMessageHistory):
"""自定义文件存储的会话历史,支持消息数量限制"""
def __init__(
self,
session_id: str
) -> None:
# 保存文件的路径
file_path_str = f"{config.CHAT_HISTORY_DIR}/{session_id}.json"
# 最大消息数量
self.max_messages = config.MAX_HISTORY_MESSAGES
self.file_path = Path(file_path_str)
# 初始化文件(不存在则创建空文件)
self._init_file()
# 初始化时裁剪历史(确保符合数量限制)
self._trim_history()
def _init_file(self) -> None:
"""确保文件存在,不存在则创建,并写入空列表"""
os.makedirs(os.path.dirname(self.file_path), exist_ok=True)
if not self.file_path.exists():
self.file_path.touch()
self._write_messages([])
# 用来将列表数据写入到文件
def _write_messages(self, messages: List[BaseMessage]) -> None:
# 将[BaseMessage,BaseMessage,...]转换为[dict,dict,...]保存到文件
serialized = messages_to_dict(messages)
self.file_path.write_text(
json.dumps(serialized, ensure_ascii=False, indent=2),
encoding="utf-8"
)
@property # 使用@property确保只读访问,防止外部修改
def messages(self) -> List[BaseMessage]:
"""读取文件中的消息列表"""
try:
items = json.loads(self.file_path.read_text(encoding="utf-8"))
# 将[dict,dict,...]转换为[BaseMessage,BaseMessage,...]
return messages_from_dict(items)
except (json.JSONDecodeError, FileNotFoundError):
# 兼容文件损坏/丢失的情况
return []
def add_message(self, message: BaseMessage) -> None:
"""添加消息并自动裁剪"""
# 1. 获取当前所有消息
current_messages = self.messages
# 2. 添加新消息
current_messages.append(message)
# 3. 如果达到最大数量,则进行裁剪
if len(current_messages) > self.max_messages:
print(f"消息数量超过 {self.max_messages},进行裁剪")
current_messages = current_messages[-self.max_messages:]
print(f"当前消息数量:{len(current_messages)}")
# 4. 一次性写入文件
self._write_messages(current_messages)
def _trim_history(self) -> None:
"""裁剪历史消息到指定数量"""
current_messages = self.messages
if len(current_messages) > self.max_messages:
# 获取列表 current_messages 中倒数第十个元素到最后一个元素,保存到文件
self._write_messages(current_messages[-self.max_messages:])
def clear(self) -> None:
"""清空所有历史消息"""
self._write_messages([])
if __name__ == "__main__":
from langchain_core.messages import HumanMessage
history = LimitedFileChatMessageHistory("test")
history.add_message(HumanMessage(content="你好")) # 人类用户消息
messages: List[BaseMessage] = history.messages
print(messages)- 还是使用我们前面章节讲解的
LimitedFileChatMessageHistory类,自动裁剪历史对话记录; - 并通过
get_session_history返回LimitedFileChatMessageHistory类对象,供后面在调用模型的时候使用。
13.5 文本数据的向量存储
在 service 包下新建 knowledge_base.py 。
在页面上传 txt 文件后,会读取其中的文本内容,我们将在这个文件中对文本内容进行处理,先计算文本内容的 md5 码,看之前有没有处理过,如果没有处理过,则将文本内容进行拆分(可能太长了),然后调用向量存储,将文本存储到向量数据库。
内容如下:
python
"""知识库服务模块"""
import os
import hashlib
from langchain_text_splitters import RecursiveCharacterTextSplitter
from datetime import datetime
from src.config import config_data as config
from src.service.vector_store import VectorStoreService
def check_md5(md5_str: str) -> bool:
"""检查传入的md5字符串是否已经被处理过
这里是将已经处理过的文件保存到文件中,在实际的生成环境应该保存到数据库
参数:
md5_str: MD5字符串
返回值:
bool: 是否已处理过
"""
if not os.path.exists(config.MD5_FILE_PATH):
return False
else:
for line in open(config.MD5_FILE_PATH, "r", encoding="utf-8").readlines():
line = line.strip()
if line == md5_str:
return True
return False
def save_md5(md5_str: str):
"""保存传入的md5字符串到文件中
这里是将已经处理过的文件保存到文件中,在实际的生成环境应该保存到数据库
参数:
md5_str: MD5字符串
"""
# 先判断文件是否存在,如果不存在则创建
if not os.path.exists(config.MD5_FILE_PATH):
open(config.MD5_FILE_PATH, "w", encoding="utf-8").close()
with open(config.MD5_FILE_PATH, "a", encoding="utf-8") as f:
f.write(md5_str + "\n")
def get_string_md5(string: str, encoding: str = "utf-8") -> str:
"""计算传入字符串的md5值
参数:
string: 要计算MD5的字符串
encoding: 编码方式,默认为utf-8
返回值:
str: MD5字符串
"""
str_bytes = string.encode(encoding=encoding)
md5 = hashlib.md5()
md5.update(str_bytes)
return md5.hexdigest()
class KnowledgeBaseService(object):
"""知识库服务类,用于管理和更新知识库"""
def __init__(self):
"""初始化知识库服务"""
# 初始化向量存储服务
self.vector_store_service = VectorStoreService()
# 初始化文本分割器
self.spliter = RecursiveCharacterTextSplitter(
chunk_size=config.CHUNK_SIZE,
chunk_overlap=config.CHUNK_OVERLAP,
separators=config.SEPARATORS,
)
def upload_by_str(self, data, filename):
"""将传入的字符串,进行向量化,保存到向量数据库中
参数:
data: 要上传的文本数据
filename: 文件名
"""
# 计算数据的MD5值
md5_hex = get_string_md5(data)
# 检查是否已经处理过
if check_md5(md5_hex):
print(f"文件{filename}已经处理过,跳过")
return
# 分割文本
if len(data) > config.MAX_SPLIT_CHAR_NUMBER:
knlnowledge_chunks = self.spliter.split_text(data)
else:
knlnowledge_chunks = [data]
# 准备元数据
metadata = {
"source": filename,
"create_time": datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
"operator": "用户001",
}
# 添加到向量数据库
self.vector_store_service.add_texts(
texts=knlnowledge_chunks,
metadatas=[metadata for _ in knlnowledge_chunks]
)
# 保存MD5值
save_md5(md5_hex)
print(f"文件{filename}已经保存到向量数据库中")
def get_retriever(self):
"""获取检索器,用于从向量存储中检索相关文档
返回值:
检索器对象
"""
return self.vector_store_service.get_retriever()
if __name__ == "__main__":
"""测试知识库服务"""
save_md5("123456")
print(check_md5("123456"))- 上面包括对文本内容的 md5 计算和存储;
- 并将文本内容拆分,封装数据,调用
VectorStoreService存储为向量数据。
13.6 调用模型对话
在 service 包下新建 rag_service.py ,主要功能是构建执行链。
后面外部获取执行链,直接调用执行链,传入问题,就可以对话了。
代码如下:
python
"""RAG (检索增强生成) 服务模块"""
from langchain_ollama import ChatOllama
from langchain_core.documents import Document
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables import RunnablePassthrough, RunnableWithMessageHistory, RunnableLambda
from src.service.chat_history_store import get_session_history
from src.config import config_data as config
from src.service.knowledge_base import KnowledgeBaseService
def print_prompt(prompt: ChatPromptTemplate):
"""打印提示模板内容"""
print("=" * 20)
print(prompt.to_string())
print("=" * 20)
return prompt
def print_data(data):
print("*" * 20)
print(data)
print("*" * 20)
return data
class RagService(object):
"""RAG 服务类,用于构建和执行 RAG 链条"""
def __init__(self):
"""初始化 RAG 服务,创建 RAG 链条"""
self.prompt_template = ChatPromptTemplate.from_messages(
[
("system", "以我提供已知的参考资料为主,简洁和专业的回答用户问题,参考资料:[{context}]"),
("system", "并且我提供用户的对话历史记录,如下:"),
MessagesPlaceholder(variable_name="history"),
("human", "请简洁的回答用户提问:{input}"),
]
)
self.chat_model = ChatOllama(model=config.CHAT_MODEL_NAME)
self.chain = self.__get_chain()
def __get_chain(self):
"""构建 RAG 链条,包括检索、格式化和生成"""
# 从知识库服务获取检索器
knowledge_base = KnowledgeBaseService()
retriever = knowledge_base.get_retriever()
def format_document(docs: list[Document]):
"""格式化文档列表,返回格式化的字符串"""
if not docs:
return "无相关参考资料"
formatted_str = ""
for doc in docs:
formatted_str += f"文档片段:{doc.page_content}\n文档元数据:{doc.metadata}\n\n"
return formatted_str
def format_for_retriever(value: dict) -> str:
return value["input"]
def format_for_prompt_template(value):
new_value = {}
new_value["input"] = value["input"]["input"]
new_value["context"] = value["context"]
new_value["history"] = value["input"]["history"]
return new_value
# chain为什么这样做,上一个章节已经详细讲过了
chain = {
"input": RunnablePassthrough(),
"context": RunnableLambda(format_for_retriever) | retriever | format_document
} | RunnableLambda(print_data) | RunnableLambda(format_for_prompt_template) | self.prompt_template | print_prompt | self.chat_model | StrOutputParser()
conversation_chain = RunnableWithMessageHistory(
chain,
get_session_history,
input_messages_key="input",
history_messages_key="history"
)
return conversation_chain
if __name__ == '__main__':
"""测试 RAG 服务"""
session_config={"configurable": {"session_id": "user_001"}}
res = RagService().chain.invoke({"input": "智能手表 Pro 的官方售价是多少"}, config=session_config)
print(res)13.7 Streamlit 简介
下面还有两个页面没有实现,一个是上传文档的页面,一个是问答页面。
这里使用 Streamlit 来实现,所以在实现之前,咱们先简单介绍一下 Streamlit。
Streamlit 是一个用于构建数据应用的 Python 库,它的设计理念是"代码即 UI",让数据科学家和开发者能够快速创建交互式 web 应用,而不需要前端开发知识。
使用 Python 脚本即可创建 web 应用,提供了多种 UI 组件,如按钮、滑块、文本输入、文件上传等,不需要 HTML、CSS 或 JavaScript 知识,适合快速构建数据可视化和机器学习应用的原型。
虽然 Streamlit 非常适合快速开发,但它也有一些局限性:
性能:每次更新都重新运行所有代码,对于大型应用可能会导致性能问题。
不适合高访问量网站:Streamlit 设计为单线程应用,不适合处理大量并发请求。对于高访问量的生产环境,建议使用更专业的 web 框架,如 Flask、Django 或 FastAPI。
状态管理:Streamlit 的状态管理相对简单,对于复杂的应用可能不够灵活。
本项目主要用于学习和演示目的,不是为生产环境设计的。如果要将 RAG 应用部署到生产环境,可能需要考虑使用更适合高并发的框架。
13.8 实现上传资料页面
在 app 包下新建 upload_app.py ,主要功能是上传文档到知识库。
python
"""知识库更新应用,项目下运行命令:streamlit run src/app/upload_app.py """
import sys
import os
# 添加项目根目录到 Python 的导入路径
root_path = os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
print(f"root_path:{root_path}")
sys.path.append(root_path)
# ===============================
import time
import streamlit as st
from src.service.knowledge_base import KnowledgeBaseService
st.title("知识库更新")
# 初始化知识库服务
if "knowledge_base_service" not in st.session_state:
st.session_state["knowledge_base_service"] = KnowledgeBaseService()
# 文件上传组件
uploaded_file = st.file_uploader(
label="请上传txt文件",
type=["txt"],
accept_multiple_files=False
)
if uploaded_file is not None:
# 获取文件信息
file_name = uploaded_file.name
file_type = uploaded_file.type
file_size = uploaded_file.size / 1024 # KB
# 显示文件信息
st.subheader(f"文件名:{file_name}")
st.write(f"文件类型:{file_type} | 文件大小:{file_size:.2f} KB")
# 读取文件内容
file_content = uploaded_file.getvalue().decode("utf-8")
# 保存到知识库
with st.spinner("保存到知识库中..."):
time.sleep(1)
result = st.session_state["knowledge_base_service"].upload_by_str(file_content, file_name)
# 显示文件内容
st.write(file_content)- 首先在页面上通过
st添加标题、文件上传等页面组件; - 因为每次页面更新都会重新执行上面的代码,所以会导致
KnowledgeBaseService()重新创建,所以使用st.session_state["knowledge_base_service"] = KnowledgeBaseService()这样的方式,将复用的数据放在st.session_state中; - 页面上传文件,获取文件的类型、文件名、内容等信息,然后调用
KnowledgeBaseService()保存到向量数据库。
在项目根目录下,运行 streamlit run src/app/upload_app.py ,显示如下:
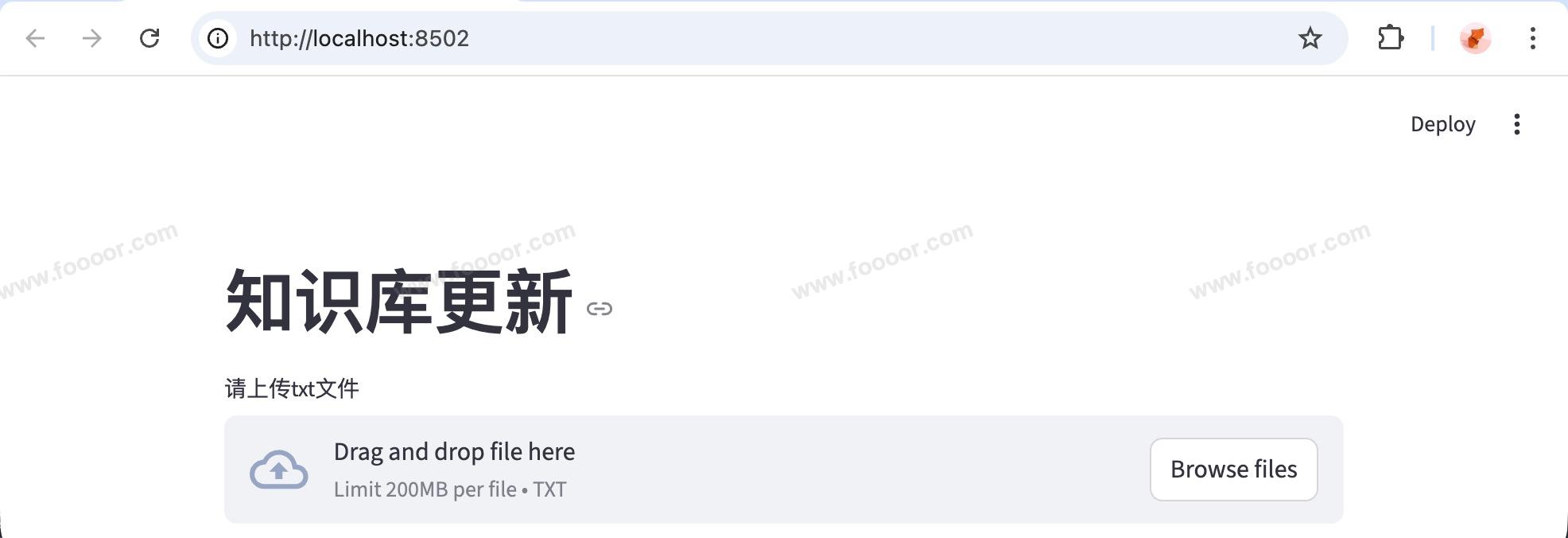
然后就可以选择文件上传到向量库了,例如我简单弄了一段文本,产品信息.txt 进行上传:
# 产品信息
## 产品名称
智能手表 Pro
## 产品价格
官方售价:¥1999
## 产品规格
- 屏幕尺寸:1.43英寸 AMOLED 显示屏
- 分辨率:466x466 像素
- 电池续航:常规使用7天,省电模式14天
- 防水等级:50米防水
- 重量:32克
## 功能特点
1. 健康监测:心率、血氧、睡眠质量监测
2. 运动模式:支持100+运动模式
3. 智能通知:接收手机推送通知
4. 支付功能:支持NFC支付
5. 语音助手:内置语音助手
## 适用人群
- 运动爱好者
- 健康管理人群
- 商务人士
## 售后服务
- 7天无理由退换
- 1年质保
- 全国联保13.9 实现对话页面
在 app 包下新建 qa_app.py ,主要功能是智能客服问答。
代码如下:
python
"""售后问答系统应用,项目下运行命令:streamlit run src/app/qa_app.py """
import sys
import os
# 添加项目根目录到 Python 的导入路径
root_path = os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
print(f"root_path:{root_path}")
sys.path.append(root_path)
# ===============================
import streamlit as st
from src.service.rag_service import RagService
from src.config import config_data as config
st.title("售后问答系统")
st.divider() # 分隔线
# messages中存储的是聊天列表,存储的一条一条和模型的聊天记录
if "messages" not in st.session_state:
st.session_state["messages"] = [
{"role": "assistant", "content": "你好,有什么我可以帮助你?"}
]
if "rag_service" not in st.session_state:
st.session_state["rag_service"] = RagService()
# 显示聊天列表,每次更新页面内容都会重新执行,所以每次都遍历将聊天记录显示在页面上
for message in st.session_state.messages:
st.chat_message(message["role"]).write(message["content"])
# 获取用户输入
prompt = st.chat_input()
if prompt:
# 将用户问题显示在页面上
st.chat_message("user").write(prompt)
# 将用户的问题添加到聊天的列表中
st.session_state["messages"].append({"role": "user", "content": prompt})
ai_res_list = []
with st.spinner("思考中..."):
# 流式获取AI回答
res_stream = st.session_state["rag_service"].chain.stream({"input": prompt}, config.SESSION_CONFIG)
def capture(generator, cache_list):
"""捕获生成器的输出并缓存"""
for chunk in generator:
cache_list.append(chunk)
yield chunk
# 将AI的回答显示在页面上
st.chat_message("assistant").write_stream(capture(res_stream, ai_res_list))
# 将AI的回答添加到聊天列表,每次页面更新都需要重新显示
st.session_state["messages"].append({"role": "assistant", "content": "".join(ai_res_list)})- 每次更新页面内容,上面的代码都会重新执行,所以需要将聊天列表保存下来,每次执行都需要遍历显示在页面上,也就是
st.session_state["messages"]中保存的内容,聊天内容分角色,显示的时候会区分用户还是 AI 的回答。 - 因为流式的回答只能读取一遍,但是我们需要将内容显示在页面上,还需要将内容添加到聊天列表中,所以这里使用
capture捕获流的内容,添加到ai_res_list,最终添加到聊天列表中。
在项目根目录下,运行 streamlit run src/app/qa_app.py ,显示如下:
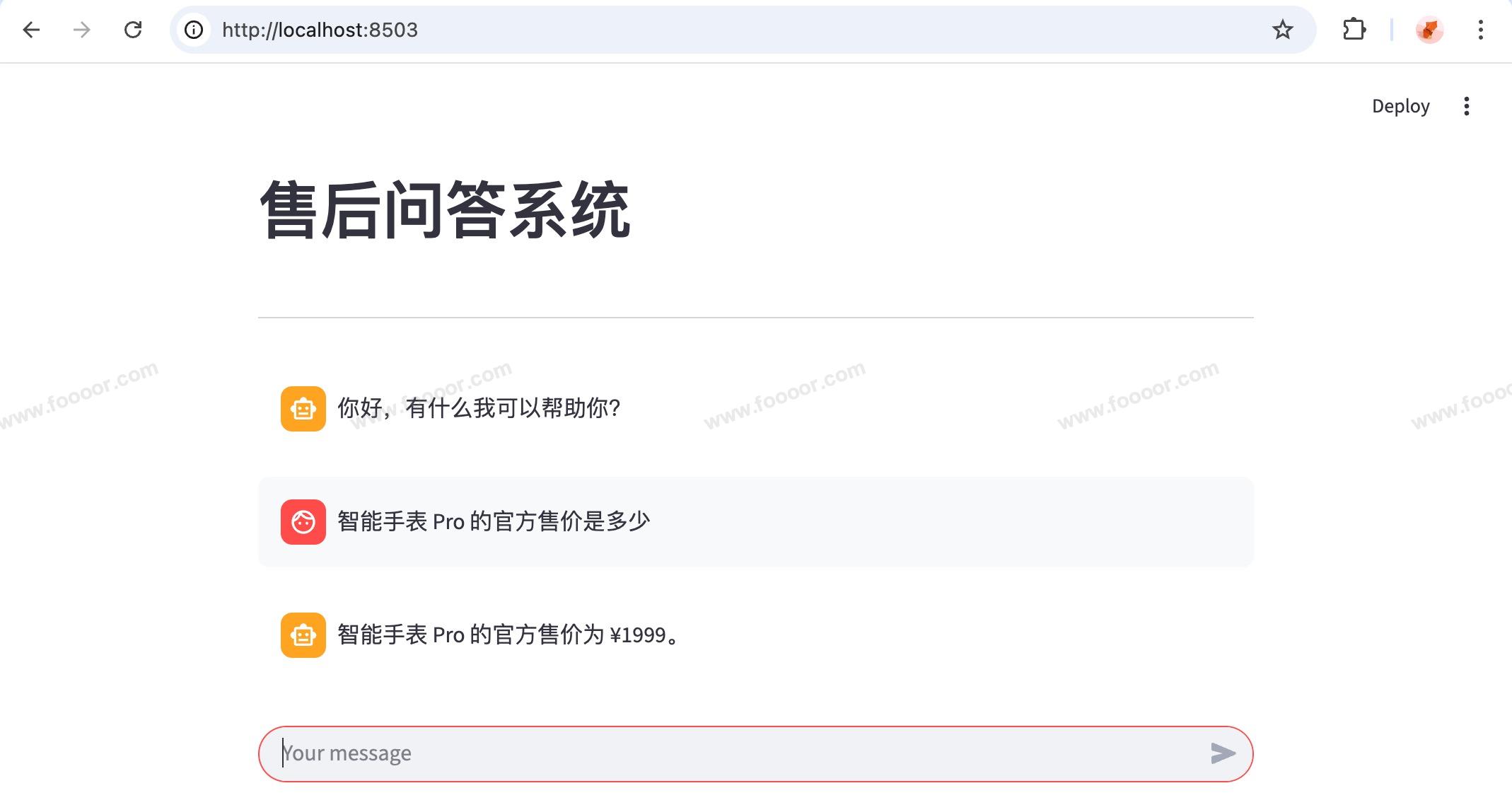
现在就可以进行聊天,回答上传的文档中的知识内容了。
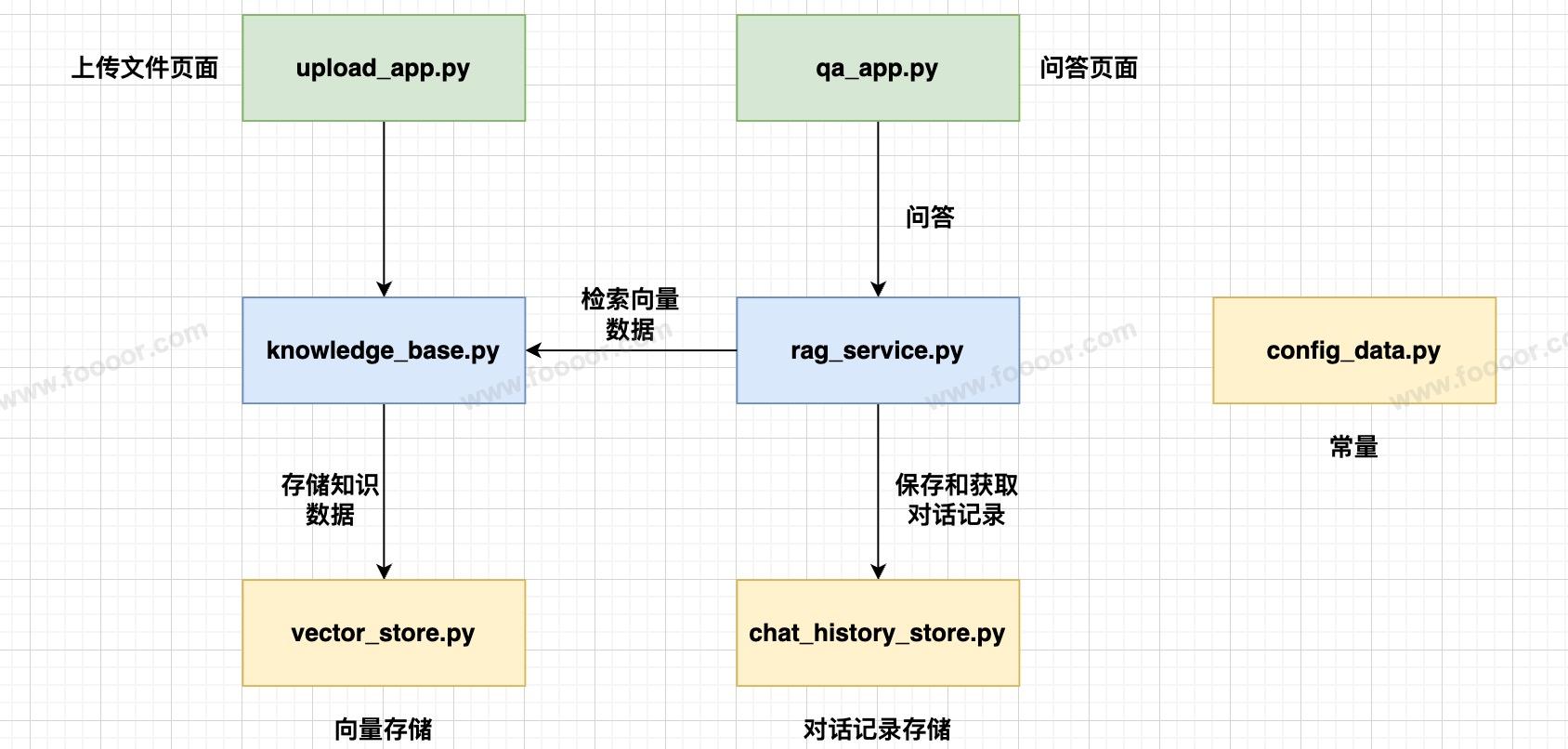
13.10 项目结构
项目结构如下: