Appearance
LangChain教程 - 12 LangChain向量存储
我们之前介绍,对于一个典型的向量存储应用,RAG 的流程如下:
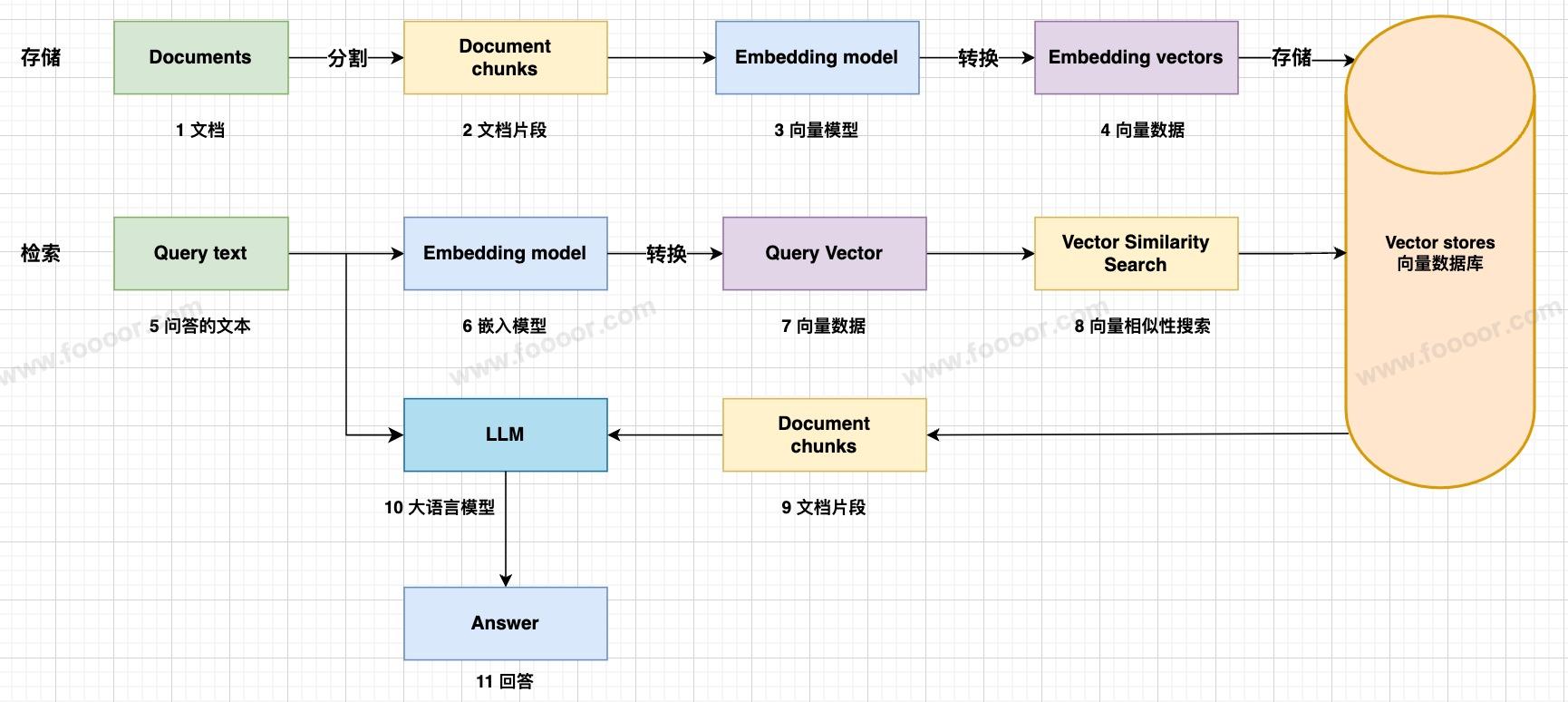
涉及到两个流程,一个是数据的存储,一个是数据的检索。
- 数据的存储:首先使用文档加载器加载文档,然后调用向量模型,将文本转换为向量数据,最后将向量存储到向量数据库;
- 数据的检索:在请求大模型进行问答的时候,首先将问答的文本使用嵌入模型进行转换,转换为向量数据,然后在向量数据库中进行相似性检索,查询到匹配的文档片段结果,最后将问答文本和检索到的文档片段作为提示词传递给大模型,让大模型基于提示词进行回答。
在前面已经学习了文档的加载,和将文本通过调用向量模型转换向量数据。现在我们来学习向量的三大核心操作:
- 向量存储(
add_documents):把文本向量持久化 / 临时保存; - 向量检索(
similarity_search):按相似度查找相关文本; - 向量删除(
delete):清理无效 / 过期的向量数据。
LangChain 支持多种向量存储方式,本文重点讲解两种最常用的场景:
- 内存存储(
InMemoryVectorStore):临时存储,程序重启后数据丢失,适合测试 / 小量数据; - 文件存储(
Chroma):持久化到本地文件,数据不丢失,适合生产 / 中量数据。
12.1 向量存储到内存
1 准备数据
下面加载文档中的数据,获取 Document ,然后将 Document 转换为向量,保存到内存。
所以先需要有一个文档,我还是将 python基础语法 作为内容进行加载。
2 向量存储操作
python
from langchain_community.document_loaders import TextLoader # 读取txt
from langchain_text_splitters import RecursiveCharacterTextSplitter # 分割
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_community.embeddings import DashScopeEmbeddings # 千问的嵌入模型
# 1.加载文档
loader = TextLoader("./data/python基础语法.txt", encoding="utf-8")
documents = loader.load()
# 2.文本分割(大文件必须切分)
splitter = RecursiveCharacterTextSplitter(
chunk_size=300,
chunk_overlap=50,
separators=["\n\n", "\n", "。", "!"]
)
# 分割文档
split_docs = splitter.split_documents(documents) # 分割为多个小Document
print(f"切分后的片段数量:{len(split_docs)}")
# 3.初始化嵌入模型,如果不传递模型,默认使用的是text-embedding-v1
embeddings = DashScopeEmbeddings(
model="text-embedding-v3"
)
# 4.初始化内存向量存储
vector_store = InMemoryVectorStore(
embedding=embeddings # 指定嵌入模型(负责文本→向量转换)
)
# 5.存入向量(自定义文档ID,方便后续删除)
vector_store.add_documents(
documents=split_docs,
# 生成自定义ID:id1、id2、id3...
ids=["id" + str(i) for i in range(1, len(split_docs) + 1)]
)
print("向量成功存入内存!")
print("-" * 20)
# 测试检索
result = vector_store.similarity_search(
"Python中注释怎么写", # 检索关键词
k=2 # 返回最相似的2个结果
)
print("result:", result)
print("-" * 20)
# 7.删除指定向量(按自定义ID删除)
vector_store.delete(["id1", "id2"])
print("已删除ID为id1、id2的向量")
print("-" * 20)
print("再次测试检索", "-" * 20)
# 再次测试检索,验证删除效果
result = vector_store.similarity_search("Python中注释怎么写", k=2)
print("result:", result)- 在上面的代码中,先通过 TextLoader 加载文档的内容,并进行文档切割,然后将切割后的 Documents 保存到内存的向量存储中,向量的存储指定使用的嵌入模型,这样会自动实现转换。
- 在检索的时候,只用
similarity_search()函数进行检索,并指定返回两个相似的结果。
执行结果:
切分后的片段数量:48
向量成功存入内存!
--------------------
result: [Document(id='id1', metadata={'source': './data/python基础语法.txt'}, page_content='# Python教程 - 2 基础语法\n\n## 2.1 注释\n\n在学习基础语法之前先介绍一下注释。\n\n我们在学习任何语言,都会有注释,注释的作用就是向别人解释我们编写的代码的含义和逻辑,使代码有更好的可读性。\n\n**注释不是程序,是不会被执行的**。\n\n注释一般分类两类,**单行注释**和**多行注释**。\n\n\n\n### 1 单行注释\n\n单行注释以 **#** 开头,井号右边为注释内容。\n\n例如:\n\n```py\n# 我是单行注释,打印Hello World\nprint("Hello World!")\n```\n\n**注意:# 号和注释内容一般建议以一个空格隔开,这是代码规范,建议大家遵守。**'), Document(id='id2', metadata={'source': './data/python基础语法.txt'}, page_content='**注意:# 号和注释内容一般建议以一个空格隔开,这是代码规范,建议大家遵守。**\n\n**单行注释一般用于对一行或一小部分代码进行解释。**\n\n\n\n### 2 多行注释\n\n多行注释是以一对三个双引号括起来,中间的内容为注释内容,注释内容可以换行。\n\n```python\n"""\n我是多行注释,\n我来哔哔两句\n"""\nprint("哔~~")\n```\n\n**多行注释一般对:Python文件、类、方法进行解释,类和方法后面我们再学习。**\n\n\n\n## 2.2 变量\n\n在代码中,数据是保存在哪里的呢?\n\n在代码中,数据需要保存在变量中,变量是在程序运行的时候存储数据用的,可以想象变量为一个盒子。')]
--------------------
已删除ID为id1、id2的向量
--------------------
再次测试检索 --------------------
result: [Document(id='id20', metadata={'source': './data/python基础语法.txt'}, page_content="打印结果:\n\n```\n<class 'NoneType'>\n```\n\nNone 是 NoneType 数据类型的唯一值,可以将 None 赋值给任何变量。\n\n\n\n### 3 变量的注解\n\n在 Python 中定义变量是不需要指定类型的。但是在 Python 中,变量注解(Variable Annotations)是 Python 3.5 引入的一个新特性,它允许开发者为变量和函数参数提供预期的类型信息。\n\n举个栗子:"), Document(id='id21', metadata={'source': './data/python基础语法.txt'}, page_content='举个栗子:\n\n```python\nname: str = "逗比" # 定义姓名\nage: int = 30 # 定义年龄\nheight: float = 1.78 # 定义升高\nis_has_jj: bool = True # 定义是否有jj\n```\n\n这个例子中,`name` 被注解为 `str` 类型,`age` 被注解为 `int` 类型,`height` 被注解为 `float` 类型,`is_has_jj` 被注解为 `bool` 类型。\n\n**但是需要注意:注解只是用来做类型提示的,不会做类型验证,不按照类型赋值也没有问题。**')]- 可以看到,第一次搜索
python中注释怎么写的时候,返回匹配到两个关于注释的段落。当删除id1/id2后,检索到的内容,就不是这两个了,而是匹配度比较低的两个段落。 - 程序运行时数据存在,关闭 / 重启后数据丢失,仅适合测试,不适合生产环境。
12.2 向量存储到文件中
下面介绍一下通过 Chroma 将向量保存到文件中。
Chroma 是轻量级开源向量数据库,支持将向量数据持久化到本地文件,数据不会因程序重启丢失。我们以「英雄技能 CSV 文件」为例,演示从 CSV 加载数据 → 向量存储 → 检索的全流程,核心需求是「通过技能描述匹配对应英雄」。
使用 Chroma 需要先安装依赖,不过之前在安装 LangChain 的时候已经安装了,如果没有执行如下指令安装一下:
pip install langchain-chroma chromadb1 准备数据
创建 hero_skills.csv 文件,内容为英雄详细信息(重点包含技能描述):
python
英雄姓名,年龄,性别,位置,核心技能,技能描述
赵云,29,男,战士,枪法+冲锋,枪法精通百鸟朝凤枪,冲锋为短距离高速突进,无视地形,擅长近战爆发
花木兰,27,女,战士,重剑+轻剑,轻剑形态灵活突进,重剑形态高伤害格挡,攻防兼备的女战士代表
高渐离,28,男,法师,魔音+冲击,魔音提升法术伤害,冲击范围法术爆发,团战AOE输出核心
不知火舞,21,女,法师,法术+舞蹈,火系法术范围攻击,舞蹈提升机动性,持续输出能力强,远程消耗
铠,30,男,坦克,剑术+格挡,剑术高伤害单体攻击,格挡减免80%伤害,防御反击能力极强,近战坦度高
钟无艳,28,女,坦克,锤击+石化,锤击范围伤害,石化控制敌方1.5秒,坦度+控制兼备,女坦克代表
孙悟空,未知,男,打野,棍术+七十二变,棍术范围击飞,七十二变可伪装,爆发+控制兼备,打野首选
阿轲,22,女,打野,隐身+背刺,隐身接近敌方,背刺造成暴击伤害,收割能力极强,女打野代表
兰陵王,32,男,刺客,隐身+收割,全程隐身侦查,近身爆发收割,秒杀脆皮的男刺客代表
上官婉儿,20,女,刺客,书法+法术,书法触发法术连招,多段位移+远程爆发,操作灵活,适合收割
张飞,35,男,辅助,咆哮+护盾,咆哮提升自身坦度,护盾为友方吸收大量伤害,团战开团核心辅助
蔡文姬,16,女,辅助,治愈+控制,治愈技能为友方回血,控制技能眩晕敌方,续航型女辅助代表2 向量存储操作
下面使用 Ollama 部署的的本地嵌入模型 qwen3-embedding:0.6b 来转换向量。
python
from langchain_community.document_loaders import CSVLoader
from langchain_chroma import Chroma
from langchain_ollama import OllamaEmbeddings
# 1.加载文档
loader = CSVLoader(
file_path="./data/hero_skills.csv",
encoding="utf-8",
csv_args={"delimiter": ","}
)
documents = loader.load()
print(f"documents数量:{len(documents)}")
# 2. 初始化嵌入模型
embeddings = OllamaEmbeddings(model="qwen3-embedding:0.6b")
# 3. 初始化向量库
persist_directory = "./chroma_hero_db" # 指定存储的目录(文件夹)
vector_store = Chroma(
persist_directory=persist_directory,
embedding_function=embeddings, # 指定嵌入模型
collection_name="hero_skills" # 指定集合名称,相当于数据库中的表名
)
# 4.存入向量(自定义文档ID,方便后续删除)
vector_store.add_documents(
documents=documents,
# 生成自定义ID:id1、id2、id3...
ids=["id" + str(i) for i in range(1, len(documents) + 1)]
)
print("向量成功存入内存!")
print("-" * 20)
# 5. 检索验证(依然是每行1个完整Document)
result = vector_store.similarity_search("近战坦度高的英雄", k=1)
print("result:", result)
print("-" * 20)
# 6.删除指定向量(按自定义ID删除)
vector_store.delete(["id2", "id3"])
print("已删除ID为id2、id3的向量")
print("-" * 20)
print("再次测试检索", "-" * 20)
result = vector_store.similarity_search("近战坦度高的英雄", k=1)
print("result:", result)- 在上面是通过 CSVLoader 来加载文件中的数据,使用本地 Ollama 部署的嵌入模型,将数据存储到 Chroma 向量数据库。
- 上面的用法和将向量存储到内存储存中,是一样的,因为它们都继承同样的父类
VectorStore,提供的方法是一样的。
12.3 查询过滤
上面在查询的时候,使用 similarity_search("近战坦度高的英雄", k=1) 方法,指定了查询的关键词和返回结果的个数。
我们在加载文档的时候,需要将指定的列添加到元数据:
python
# 1.加载文档
loader = CSVLoader(
file_path="./data/hero_skills.csv",
encoding="utf-8",
csv_args={"delimiter": ","},
# 保留元数据:位置/性别(用于过滤)
metadata_columns=["位置", "性别"]
)然后在查询的时候进行过滤:
python
result = vector_store.similarity_search("近战坦度高的英雄", k=1, filter={"性别": "女"})12.4 结合提示词模板使用
下面将模型、提示词模板结合上面的向量的存储和检索进行使用。
包含了两个操作:
存储 :从 CSV 文件加载内容,然后使用向量模型转换为向量数据保存到数据库,然后再调用向量数据库检索数据;
检索 :将用户提问和检索到的数据,传递给模板,生成提示词,然后调用大模型;
python
from langchain_community.document_loaders import CSVLoader
from langchain_chroma import Chroma
from langchain_ollama import OllamaEmbeddings
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_ollama import ChatOllama
# 1.加载文档
loader = CSVLoader(
file_path="./data/hero_skills.csv",
encoding="utf-8",
csv_args={"delimiter": ","},
# 保留元数据:位置/性别(用于过滤)
metadata_columns=["位置", "性别"]
)
documents = loader.load()
print(f"documents数量:{len(documents)}")
# 2. 初始化嵌入模型
embeddings = OllamaEmbeddings(model="qwen3-embedding:0.6b")
# 3. 初始化向量库
persist_directory = "./chroma_hero_db" # 指定存储的目录(文件夹)
vector_store = Chroma(
persist_directory=persist_directory,
embedding_function=embeddings, # 指定嵌入模型
collection_name="hero_skills" # 指定集合名称,相当于数据库中的表名
)
# 4.存入向量(自定义文档ID,方便后续删除)
vector_store.add_documents(
documents=documents,
# 生成自定义ID:id1、id2、id3...
ids=["id" + str(i) for i in range(1, len(documents) + 1)]
)
print("向量成功存入内存!")
print("-" * 20)
input = "近战坦度高的英雄"
# 5. 检索验证(依然是每行1个完整Document)
result = vector_store.similarity_search(input, k=1)
# 从向量库查询到参考资料
reference_text = ""
# 得到的结果是Document数组
for doc in result:
reference_text += doc.page_content
print("reference_text:", reference_text)
print("-" * 20)
# 5. 创建聊天模型
model = ChatOllama(model="qwen3:0.6b")
strOutputParse = StrOutputParser()
# 6. 创建聊天提示词模板
chat_prompt_template = ChatPromptTemplate.from_messages(
[
("system", "以我提供的参考资料为主进行回答问题,参考资料:{context}"),
("human", "用户提问:{input}")
]
)
chain = chat_prompt_template | model | strOutputParse
response = chain.invoke({"input": input, "context": reference_text})
print("回答:", response)- 其实前面的代码基本不变,只是通过问题在向量库中检索到结果后,将这个结果整理为参考资料;
- 然后创建模型和提示词模板,将参考资料传递给提示词模板,然后进行提问就可以了。
执行结果:
documents数量:12
向量成功存入内存!
--------------------
reference_text: 英雄姓名: 铠
年龄: 30
核心技能: 剑术+格挡
技能描述: 剑术高伤害单体攻击,格挡减免80%伤害,防御反击能力极强,近战坦度高
--------------------
回答: 铠的近战坦度表现非常突出。她的核心技能「剑术」在单体攻击方面具有极高的伤害输出能力,同时由于格挡减免的机制,即使面对高伤害的攻击,铠也能在防御反击中保持较强的战斗力。这种技能组合使得她在近战时坦度极高,能够有效应对多种战斗情况。12.5 将检索加入到执行链
上面已经学习了如何结合提示词模板使用向量存储,但检索部分是在执行链之外的:
python
# 检索
result = vector_store.similarity_search(input, k=1)
# 创建执行链
chain = chat_prompt_template | model | strOutputParse现在来看看,如何将检索也加入到执行链中,构建一个完整的流程。
1 检索器Retriever
要加入执行链,得是 Runnable 接口的实例,我们可以使用 vector_store 向量库转换为检索器 Retriever:
python
vector_store = Chroma(
persist_directory=persist_directory,
embedding_function=embeddings,
collection_name="hero_skills"
)
# 1.通过向量库获取检索器
retriever = vector_store.as_retriever(
search_kwargs={"k": 2} # 设置默认返回2个结果
)
# 2. 通过检索器去检索
results = retriever.invoke("近战坦度高的英雄")
print("检索结果:")
for i, doc in enumerate(results):
print(f"{i+1}. {doc.page_content}")- 检索器 Retriever 是 LangChain 中用于从向量存储中检索相关文档的组件,它实现了 Runnable 接口,可以直接加入到执行链中。
现在已经具有了加入执行链的条件,执行链首先执行查询,从向量库中查询数据,然后将查询结果作为参考资料交给提示词模板,生成提示词传递给 model,最终得到结果,所以执行链如下:
python
chain = retriever | chat_prompt_template | model | strOutputParse但是这里有两个问题:
第一个问题:
就是第一个组件的输出是第二个组件的输入,这里 retriever 的输出无法和 chat_prompt_template 模板的输入匹配:
retriever:输入是字符串,输出是list[Document];chat_prompt_template:输入是{字典},输出是PromptValue。
所以需要将 retriever 的输出结果 list[Document] 转换为 {字典} ,然后再给模板。
第二个问题:
用户提问传递给 retriever 了,输出参考资料,但是在第二步,需要将用户提问和参考资料一起传递给 chat_prompt_template ,此时 chat_prompt_template 的输入只有第一步 retriever 的输出,拿不到用户提问了。
处理上面两个问题,需要借助一下 RunnablePassthrough 。
2 RunnablePassthrough
RunnablePassthrough 是 LangChain 中的一个组件,用于在执行链中传递数据,它不会修改输入,而是直接返回输入。
举个栗子:
python
from langchain_core.runnables import RunnablePassthrough
r = RunnablePassthrough()
result = r.invoke("hello")
print(result) // hello- 输出结果就是输入,执行流程:
输入 → RunnablePassthrough → 输出,啥也没干。
这有什么用呢,其实字典也可以加入执行链,只要执行链前后有一个 Runnable 接口实现,会自动将 Map 转换为 RunnableMap。
所以可以将字典加入到执行链:
python
from langchain_core.runnables import RunnablePassthrough, RunnableLambda
# 自定义函数
def print_data(data):
return data
# 将普通函数转换为 Runnable
runnable_lambda = RunnableLambda(print_data)
# 构建一个执行链
chain = {"input": RunnablePassthrough(), "context": RunnablePassthrough()} | runnable_lambda
result = chain.invoke("hello")
print(result)- 在上面的代码中,构建了一个执行链,执行链第一个组件是一个字典,其中有两个属性,会接收到执行链调用时候的方法参数,所以字典会变成
{'input': 'hello', 'context': 'hello'}。 - 然后将第一个组件的字典数据,交给
runnable_lambda函数打印。 - 只有执行链中有 Runnable 实现,才会将
Map转换为RunnableMap,否则 Map 需要时候用RunnableMap({...})这样显式来定义。
通过上面的例子可以看到 RunnablePassthrough 就是接收当前执行节点的输入数据,上面接收的是字符串类型,其实可以是任意类型的数据。
3 将检索加入执行链
有了 RunnablePassthrough 我们再看一下,如何将检索加入到之前的执行链。
代码如下:
python
from langchain_community.document_loaders import CSVLoader
from langchain_chroma import Chroma
from langchain_core.runnables import RunnablePassthrough
from langchain_ollama import OllamaEmbeddings
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_ollama import ChatOllama
# ============ 1.索引 ==================
# 1.加载文档
loader = CSVLoader(
file_path="./data/hero_skills.csv",
encoding="utf-8",
csv_args={"delimiter": ","},
# 保留元数据:位置/性别(用于过滤)
metadata_columns=["位置", "性别"]
)
documents = loader.load()
print(f"documents数量:{len(documents)}")
# 2. 初始化嵌入模型
embeddings = OllamaEmbeddings(model="qwen3-embedding:0.6b")
# 3. 初始化向量库
persist_directory = "./chroma_hero_db" # 指定存储的目录(文件夹)
vector_store = Chroma(
persist_directory=persist_directory,
embedding_function=embeddings, # 指定嵌入模型
collection_name="hero_skills" # 指定集合名称,相当于数据库中的表名
)
# 4.存入向量(自定义文档ID,方便后续删除)
vector_store.add_documents(
documents=documents,
# 生成自定义ID:id1、id2、id3...
ids=["id" + str(i) for i in range(1, len(documents) + 1)]
)
print("向量成功存入内存!")
print("-" * 20)
# ============ 2.检索 ==================
def format_documents(documents: list):
# 从向量库查询到参考资料
reference_text = ""
# 得到的结果是Document数组
for doc in documents:
reference_text += doc.page_content
print("reference_text:", reference_text)
# 1.通过向量库获取检索器
retriever = vector_store.as_retriever(
search_kwargs={"k": 2} # 设置默认返回2个结果
)
# 2. 创建聊天模型
model = ChatOllama(model="qwen3:1.7b")
strOutputParse = StrOutputParser()
# 3. 创建聊天提示词模板
chat_prompt_template = ChatPromptTemplate.from_messages(
[
("system", "以我提供的参考资料为主进行回答问题,参考资料:{context}"),
("human", "用户提问:{input}")
]
)
# 构建执行链
chain = {"input": RunnablePassthrough(), "context": retriever | format_documents} | chat_prompt_template | model | strOutputParse
response = chain.invoke("近战坦度高的英雄")
print("回答:", response)关键代码是下面这句:
python
chain = {"input": RunnablePassthrough(), "context": retriever | format_documents} | chat_prompt_template | model | strOutputParsechat_prompt_template 中定义了 context 和 input 两个参数,并接收字典类型,所以:
python
{"input": RunnablePassthrough(), "context": retriever | format_documents}就是为了构建 {"input":"...", "context":"..."} 字典类型的数据,RunnablePassthrough() 就是获取到用户提问的字符串,retriever | format_documents 是一个子 chain 链,用户的提问字符串也会传递给 retriever ,调用 retriever 获取到 list[Document] ,然后传递给 format_documents 方法进行数据格式化,最终得到字段数据,再往后传递。
12.6 整合对话历史记录
上面执行链已经完整了,下面对执行链添加历史记录功能。
首先修改提示词模板:
python
from langchain_core.prompts import MessagesPlaceholder
# 修改提示词模板,添加历史记录
chat_prompt_template = ChatPromptTemplate.from_messages(
[
("system", "以我提供的参考资料为主进行回答问题,参考资料:{context}"),
MessagesPlaceholder("chat_history"), # 历史记录会添加到这个位置
("human", "用户提问:{input}")
]
)然后使用 RunnableWithMessageHistory 包装 chain:
python
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_community.chat_message_histories import FileChatMessageHistory
# 从文件中获取会话历史记录
def get_session_history(session_id: str):
# 每个session_id对应一个文件,保存在当前目录chat_history下
file_path = f"./chat_history/{session_id}.json"
return FileChatMessageHistory(file_path=file_path)
# 包装成带记忆的链
with_memory_chain = RunnableWithMessageHistory(
chain,
get_session_history,
input_messages_key="input",
history_messages_key="chat_history"
)
session_id = "user1"
response = with_memory_chain.invoke("近战坦度高的英雄", config={"configurable": {"session_id": session_id}})
print("回答:", response)但是执行后,发现代码报错:
ValueError: The input to RunnablePassthrough.assign() must be a dict.这是因为传递给 RunnableWithMessageHistory 参数的类型需要为字典类型,所以修改调用时候的 input 参数为字典类型:
python
response = with_memory_chain.invoke(input={"input": "近战坦度高的英雄"}, config={"configurable": {"session_id": session_id}})经过上面的修改,仍然有问题,因为 chain 是下面这样的:
python
chain = {"input": RunnablePassthrough(), "context": retriever | format_documents} | chat_prompt_template | model | strOutputParse在进行数据传递的时候,传递给链的参数就是调用链的时候传递的字典参数了,也就是 {"input": "近战坦度高的英雄"} ,其中除了包含了 input ,还会新增一个 history 属性,history 参数是 RunnableWithMessageHistory 自动添加的,所以传递给 RunnablePassthrough() 和 retriever 的参数格式如下:
json
{
'input': '近战坦度高的英雄', // 用户问题
'history': [...] // 历史数据
}于是问题又出现了,因为 retriever 是只能接收字符的,现在接收的是上面的字典类型 {"input":"xxx", "history": []},所以需要将用户提问从上面传递的参数中提取出来,然后再传递给 retriever ,于是添加一个参数,并修改 chain:
python
def format_for_retriever(value: dict) -> str:
return value["input"]
# 构建执行链
chain = {
"input": RunnablePassthrough(),
"context": RunnableLambda(format_for_retriever) | retriever | format_documents
} | chat_prompt_template | model | strOutputParse- 在
retriever前面添加了RunnableLambda(format_for_retriever),也就是将{"input":"xxx", "history": []}格式数据中的input提取出来,然后传递给retriever。
但是还是有问题,因为传递给提示词模板的需要如下格式:
json
{
"input": "近战坦度高的英雄", // 用户问题
"context": "参考资料"
"history": [...] // 历史数据,RunnableWithMessageHistory自动添加的
}本来 history 是 RunnableWithMessageHistory自动添加的,但是在 chain 链最前面使用的是我们自己定义的字典 {"input":"xxx", "context":"xxx"} ,而且 RunnablePassthrough() 只是透传,所以到了提示词这里,参数变成如下形式了:
json
{"input": {"input": "近战坦度高的英雄", "history":[]}, "context": "参考资料"}格式不对了,所以需要重新修改格式:
python
# 转换参数给提示词模板
def format_for_prompt_template(value):
new_value = {}
new_value["input"] = value["input"]["input"]
new_value["context"] = value["context"]
new_value["chat_history"] = value["input"]["chat_history"]
return new_value
chain = {
"input": RunnablePassthrough(),
"context": RunnableLambda(format_for_retriever) | retriever | format_documents
} | RunnableLambda(format_for_prompt_template) | chat_prompt_template | model | strOutputParse到这里,问题才算解决。
有点乱,重新梳理一下:
python
首先调用执行链:response = with_memory_chain.invoke(input={"input": "近战坦度高的英雄"}, config={"configurable": {"session_id": session_id}})
传递的参数是 {"input": "近战坦度高的英雄"},因为 RunnableWithMessageHistory 的封装,参数变成 {"input": "近战坦度高的英雄", "history":[xxx]}
参数:{"input": "近战坦度高的英雄", "history":[xxx]} 被 chain 中的第一个组件:
{"input": RunnablePassthrough(),"context": RunnableLambda(format_for_retriever) | retriever | format_documents}
接收到,也就是被 RunnablePassthrough() 和 format_for_retriever 接收到
先说 format_for_retriever,参数被 format_for_retriever 接收到,因为 retriever 接收的是字符串,所以从参数中取出 input 给子链中的 retriever,去检索参考资料。
参数还被 RunnablePassthrough() 接收到,所以第一个组件最终输出是:
{"input": {"input": "近战坦度高的英雄", "history":[]}, "context": "参考资料"}
继续向下传递,到了提示词模板,提示词模板需要接收 {"input": "近战坦度高的英雄", "context": "参考资料", "history":[xxx]} 格式的参数,所以这里格式不对了,重新使用 format_for_prompt_template 调整格式参数。最终代码如下:
python
from langchain_community.document_loaders import CSVLoader
from langchain_chroma import Chroma
from langchain_core.runnables import RunnablePassthrough
from langchain_ollama import OllamaEmbeddings
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_ollama import ChatOllama
from langchain_core.prompts import MessagesPlaceholder
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_community.chat_message_histories import FileChatMessageHistory
from langchain_core.runnables import RunnableLambda
# ============ 1.索引 ==================
# 1.加载文档
loader = CSVLoader(
file_path="./data/hero_skills.csv",
encoding="utf-8",
csv_args={"delimiter": ","},
# 保留元数据:位置/性别(用于过滤)
metadata_columns=["位置", "性别"]
)
documents = loader.load()
print(f"documents数量:{len(documents)}")
# 2. 初始化嵌入模型
embeddings = OllamaEmbeddings(model="qwen3-embedding:0.6b")
# 3. 初始化向量库
persist_directory = "./chroma_hero_db" # 指定存储的目录(文件夹)
vector_store = Chroma(
persist_directory=persist_directory,
embedding_function=embeddings, # 指定嵌入模型
collection_name="hero_skills" # 指定集合名称,相当于数据库中的表名
)
# 4.存入向量(自定义文档ID,方便后续删除)
vector_store.add_documents(
documents=documents,
# 生成自定义ID:id1、id2、id3...
ids=["id" + str(i) for i in range(1, len(documents) + 1)]
)
print("向量成功存入内存!")
print("-" * 20)
# ============ 2.检索 ==================
def format_documents(documents: list):
# 从向量库查询到参考资料
reference_text = ""
# 得到的结果是Document数组
for doc in documents:
reference_text += doc.page_content
print("reference_text:", reference_text)
return reference_text
# 1.通过向量库获取检索器
retriever = vector_store.as_retriever(
search_kwargs={"k": 2} # 设置默认返回2个结果
)
# 2. 创建聊天模型
model = ChatOllama(model="qwen3:1.7b")
strOutputParse = StrOutputParser()
# 3. 创建聊天提示词模板
chat_prompt_template = ChatPromptTemplate.from_messages(
[
("system", "以我提供的参考资料为主进行回答问题,参考资料:{context}"),
MessagesPlaceholder("chat_history"), # 历史记录会添加到这个位置
("human", "用户提问:{input}")
]
)
def print_data(data):
print("*"*20)
print(data)
print("*"*20)
return data
def format_for_retriever(value: dict) -> str:
return value["input"]
def format_for_prompt_template(value):
new_value = {}
new_value["input"] = value["input"]["input"]
new_value["context"] = value["context"]
new_value["chat_history"] = value["input"]["chat_history"]
return new_value
# 构建执行链
chain = {
"input": RunnablePassthrough(),
"context": RunnableLambda(format_for_retriever) | retriever | format_documents
} | RunnableLambda(print_data) | RunnableLambda(format_for_prompt_template) | chat_prompt_template | print_data | model | strOutputParse
# 从文件中获取会话历史记录
def get_session_history(session_id: str):
# 每个session_id对应一个文件,保存在当前目录chat_history下
file_path = f"./chat_history/{session_id}.json"
return FileChatMessageHistory(file_path=file_path)
# 5. 包装成带记忆的链
with_memory_chain = RunnableWithMessageHistory(
chain,
get_session_history,
input_messages_key="input",
history_messages_key="chat_history"
)
session_id = "user1"
response = with_memory_chain.invoke(input={"input": "近战坦度高的英雄"}, config={"configurable": {"session_id": session_id}})
print("回答:", response)- 在上面的代码中,还添加了打印参数的方法
print_data,方便将参数打印出来,看看参数格式对不对。
到目前为止整个 RAG 流程中每个节点都学习了,后面通过一个 RAG 项目将所有的内容整合起来。